

嗨,大家好!您在下载开源大语言模型(LLM)的时候是否为了模型的规格大小而犯愁?我的显卡到底能跑多大的LLM呢?这些问题是不是一直困扰着你。以前,有经验的AI开发者或者使用者通常会查看模型的容量大小来猜测是否能满足自己的显卡内存,当然这是一个非常不严谨的“计算方式”。那么,今天我来分享一个实例,通过严谨的公式计算就能算出什么样的大模型适合你的显卡。
公式及原理
计算公式(公式的提供者应该是叫Sam Stoelinga):
M = ((P * 4B) / (32/Q)) * 1.2
| 符号 | 描述 |
|---|---|
| M | Memory Required(所需内存,MR) |
| P | Parameter Count(参数数量,PC) |
| 4B | 4 Bytes per Parameter(每参数4字节,BPP) |
| 32 | 32 Bits per 4 Bytes(4字节32位,BPB) |
| Q | Quantization Bits(量化位数,QB) |
| 1.2 | Overhead Factor(开销因子,OF) |
在这个公式中:
- P(参数数量):这是第一个变量值,表示模型的参数数量(以十亿为单位)。
- Q(量化位数):这是第二个变量值,表示模型量化后每个参数使用的位数。
- 4B 和 32 是常量:
- 4B 表示在全精度(32位)表示中每个参数占用 4 字节。
- 32 表示标准的 4 字节包含 32 位。
- 1.2 是固定的开销因子,表示额外 20% 的内存需求。
计算过程:
- (P * 4B) 计算出模型在全精度下的总字节数。
- (32/Q) 计算出量化后每个参数所占空间相对于全精度的比例。
- ((P * 4B) / (32/Q)) 得出量化后模型的实际大小。
- 最后乘以 1.2 考虑了额外的 20% 开销。
实例展示
当我们有了这些参数和计算公式之后呢,就可以去找目前最强大的Claude3.5-Sonnet了,让它帮我们编写一个小小计算器应用,过程就不展示了,花了20分钟左右,写了一个html,已经可以公开使用了,分为本地版本和在线版本,都免费开放,代码也可以随便改
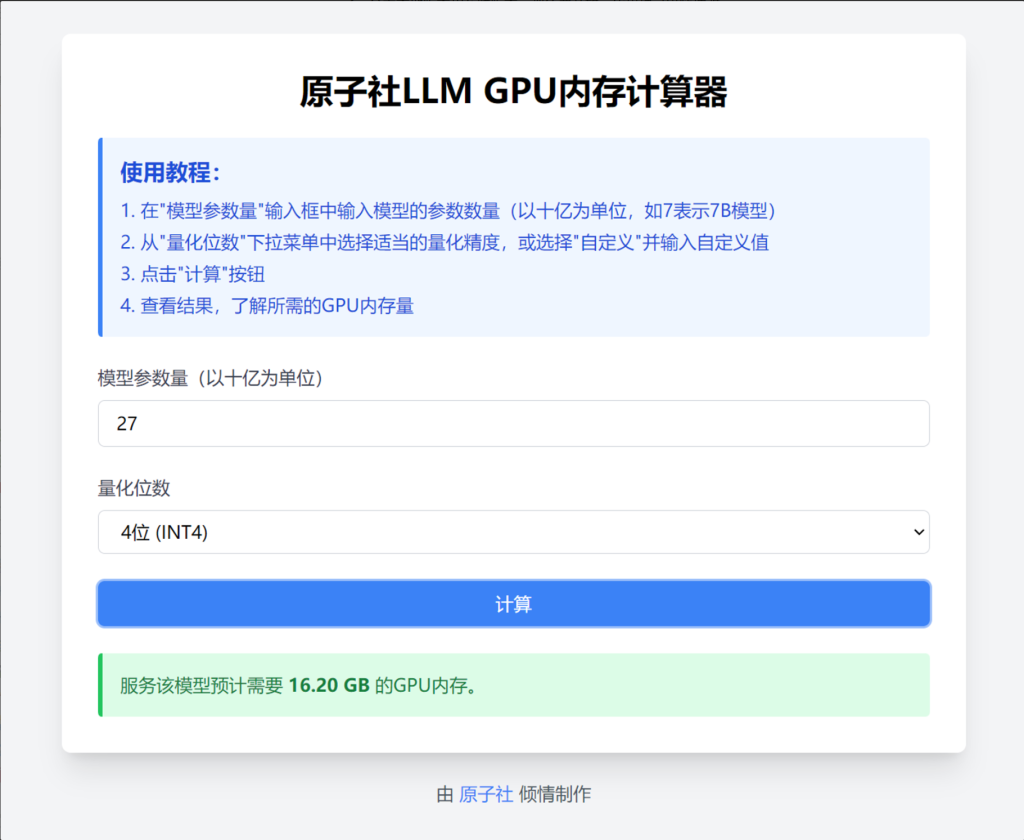
以gemma2:27b_Q4_0这种格式的模型为例,其中27b为模型参数量,Q4为模型量化位数,所以只需要填入4位就可以开始计算了,最终得出16.2GB显卡内存。
本地版本网盘链接: https://pan.baidu.com/s/1yrI3HWA6A9gwy8Z9qyZzXQ?pwd=wgba

