

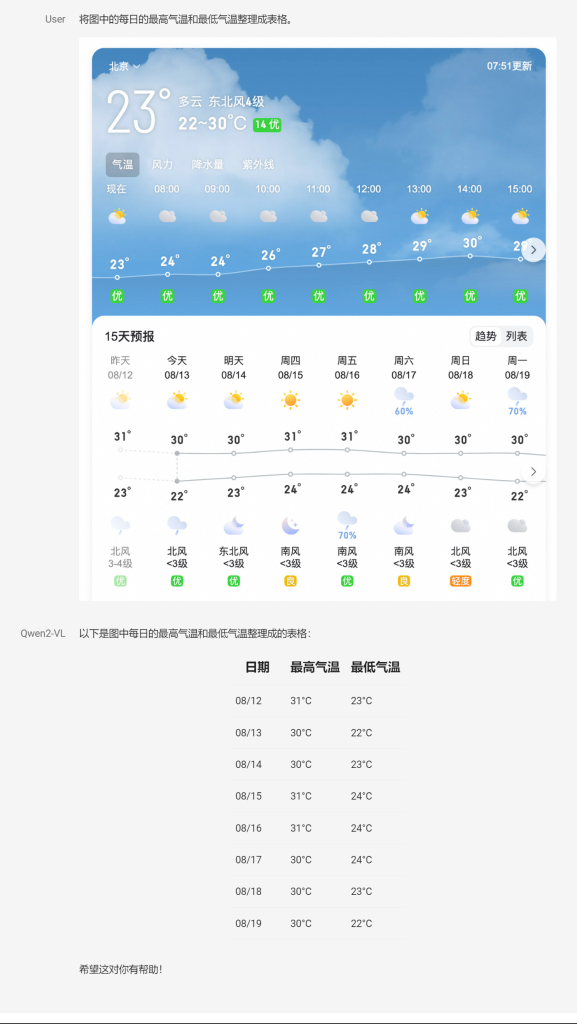
嗨,大家好!今天向大家分享一下阿里最新开源的Qwen2-VL视觉语言模型(多模态),这个模型是基于Qwen2打造的,性能相比于上一代Qwen-VL要提升非常高,以下是这款模型的亮点:
- 推出3种不同规模的多模态模型,包括Qwen2-VL-2B、Qwen2-VL-7B和Qwen2-VL-72B;
- 显著提升图像和视频理解能力,支持20分钟以上的长视频理解;
- 增强复杂推理和决策能力,可用于移动设备、机器人等操作;
- 扩展多语言支持,除中英文外,新增对多种欧洲语言、日语、韩语、阿拉伯语等的支持;
- 采用创新架构,如动态分辨率处理和多模态旋转位置嵌入(M-ROPE)。
已在Hugging Face和ModelScope上开源2B和7B模型,并提供72B模型的API服务。
模型基础信息
Qwen2-VL系列包含3种规模的模型,具体如下:
| 模型 | 参数量 (B) | 上下文长度 (K tokens) |
|---|---|---|
| Qwen2-VL-2B | 2 | 32 |
| Qwen2-VL-7B | 7 | 128 |
| Qwen2-VL-72B | 72 | 128 |
所有模型均采用了GQA技术,实现推理加速和显存占用降低。7B和72B模型支持高达128K tokens的上下文长度,在长序列视觉-语言理解任务中表现卓越。
GQA,即Grouped-Query Attention(分组查询注意力),是一种在大型语言模型中使用的注意力机制。它是对传统的多头注意力(Multi-Head Attention, MHA)和多查询注意力(Multi-Query Attention, MQA)的扩展,通过将查询头分组,每个组共享一个公共的键(Key)和值(Value)投影,从而在计算效率和模型表达能力之间提供灵活的权衡
多模态能力全面提升
Qwen团队在多个关键领域实现了显著突破:
- 图像理解: 在DocVQA、TextVQA等基准测试中达到SOTA水平,展现出优秀的文档和场景文字理解能力。
- 视频理解: 支持20分钟以上长视频理解,在Video-MME、EgoSchema等测试中表现优异。
- 多语言视觉-语言处理: 在MTVQA等多语言视觉问答任务中,Qwen2-VL-72B超越GPT-4和Claude 3 Opus等强大对手。
- 复杂视觉推理: 在MathVista等需要复杂视觉推理的任务中取得领先成绩。
- Agent能力: 在各类视觉Agent任务(如Android操作、AI2THOR等)中展现出色表现,为未来的视觉交互应用奠定基础
图片理解及推理示例



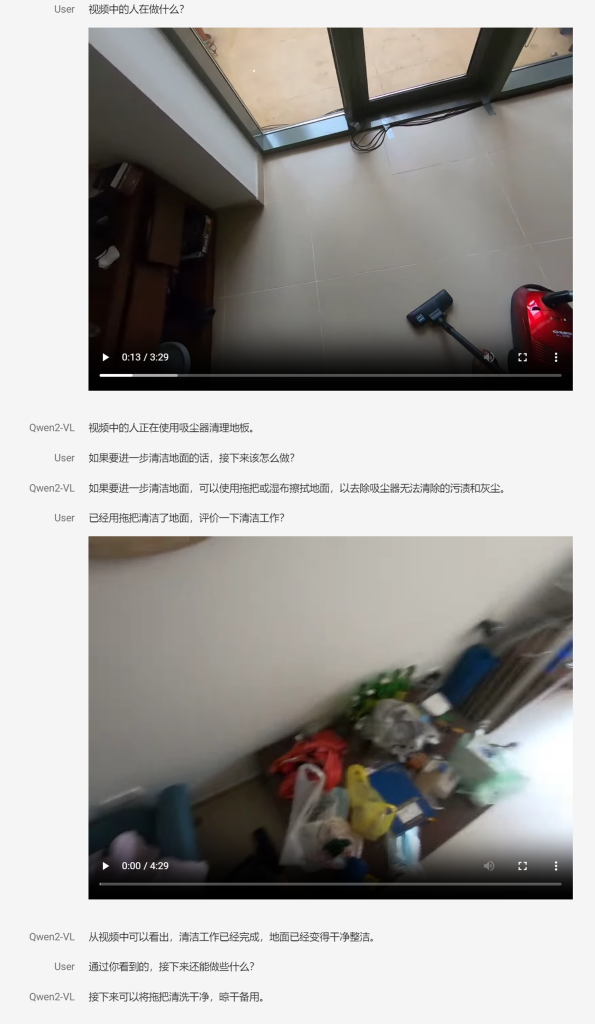
视频理解及推理示例
复杂视觉推理示例

外部工具调用能力示例
由于公众号展示图片有限制,所以我只截取了部分示例,如要看全部示例可在GitHub上查看,链接在文尾。
创新架构
Qwen2-VL引入了两项关键技术创新:
- 动态分辨率处理: 采用Naive Dynamic Resolution技术,可处理任意分辨率的图像输入,更接近人类视觉处理方式。
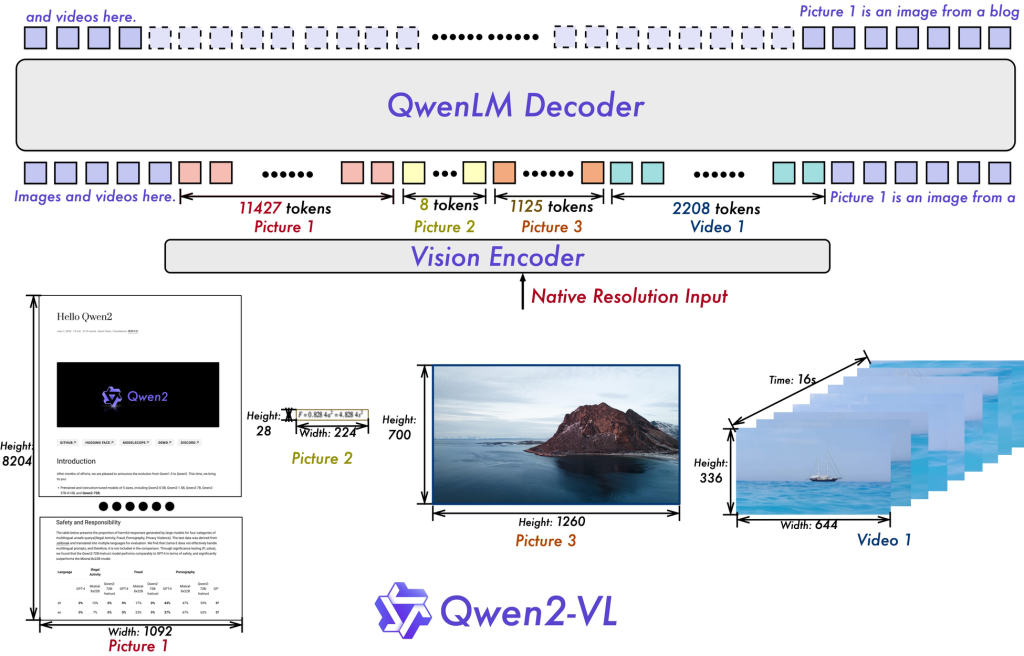
2. 多模态旋转位置嵌入(M-ROPE): 创新性地将位置嵌入分解为1D文本、2D视觉和3D视频位置信息,大幅提升多模态处理能力。

如何使用Qwen2-VL
线上版本:国外抱抱脸,国内魔搭社区。

- 进入魔搭社区,导航栏选中“创空间”,进入该页点击Qwen2-7B-VL-demo空间卡片。

2. 上传文件,提出问题。
总个结
说起开源的视觉模型,真是让人感慨啊。回想起来,LLaVA算是开源界的先驱了,虽然玩玩还行,但想用到实际工作中还是差点火候。不过现在好了,阿里的Qwen2-VL的开源,这下可真是给业界带来了一股新鲜空气。 你看那些演示,简直让人惊叹不已。它对图像的理解和推理能力,啧啧,真是厉害得不得了。我觉得,这可不仅仅是小打小闹了,而是要在行业里掀起一场风暴啊。 先说图片标注这行吧,估计很多人要坐不住了。Qwen2-VL这么厉害,怕是要把不少人的饭碗都给端了。再看看机器人行业,那可真是要腾飞了。想想看,机器人有了这么强的视觉能力,那不就跟开了挂一样吗? 不过话说回来,这种技术进步也给我们带来了新的思考。比如说,我们人类在这个AI迅速发展的时代,该如何适应和进化呢?还有,这种强大的视觉AI会不会给隐私安全带来新的问题?
稍后会带来如何在本地使用Qwen2-7B-VL。
开源地址:https://github.com/QwenLM/Qwen2-VL

