

前言
Stable Diffusion(稳定扩散)严格说来它是一个由几个组件(模型)构成的系统,而非单独的一个模型。我以最常见的文生图为例,解释下 Stable Diffusion 的整体架构,和工作原理。
如何工作
当我们输入一句 prompt 后,比如“a dog,standing on the grass,”,Stable Diffusion 会生成一张狗子站在草地的图,看似只有一步:
但实际上,整个生成的过程经过三个大的步骤。我会先概括地介绍这三大步骤分别是什么,先让大家对 Stable Diffusion 有一个整体的理解,然后再细讲里面的细节:
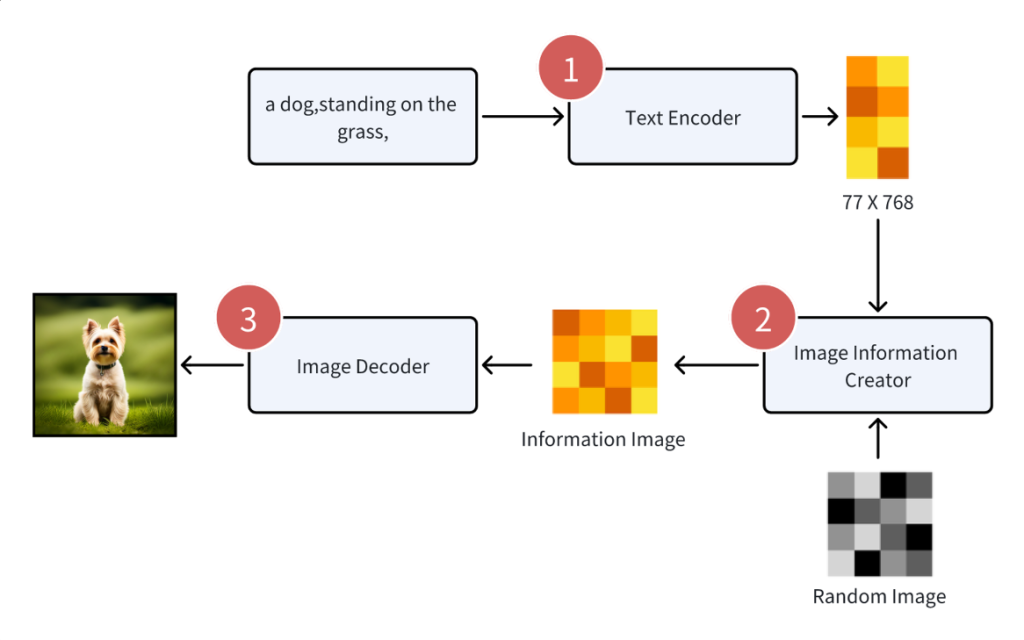
- 首先,用户输入的 Prompt 会被一个叫Text Encoder(文本编译器) 的东西编译成一个个的词特征向量。此步骤下会输出 77 个等长的向量,每个向量包含 768 个维度。各位同学可以简单将其理解为「将文本转化为机器能识别的多组数字信息」。
- 接着,这些特征向量会和一张随机图(可以简单理解这是一张老式电视机的雪花图,或充满信息噪声的图),一起放到 Image Information Creator 里。在这一步,机器会将这些特征向量和随机图先转化到一个Latent Space(潜空间)里,然后根据这些特征向量,将随机图「降噪」为一个「中间产物」。你可以简单理解,此时的「中间产物」是人类看不懂的「图」,是一堆数字信息,但此时这个中间产物所呈现的信息已经是一只狗站在草地上了。
- 最后,这个中间产物会被Image Decoder(图片解码器)解码成一张真正的图片。
如果将以上的三大步骤可视化的话,会是这样:

总结一下,简单理解,就是用户输入了一段 Prompt 指令,机器会按照这个指令,在一个潜空间里,将一张随机图降噪为一张符合指令的图片。整个过程,与其说 AI 是在「生成」图片,不如称其为「雕刻」更合适。
所有图片都存在了一张充满噪点的图片里,AI 只是把不要的部分去掉了。所以如果你用同样是 Diffusion Model 搭建的 Midjourney 话,你会看到如下的过程,首先是一张模糊甚至黑色的图片,然后图片会一步步变得越来越清晰,这就是我前面所说的「降噪」或者「雕刻」的过程:
💡 你可能好奇,为何前面的解释里,Stable Diffusion 最后是直接出图,而不像 Midjourney 那样?实际上,在第二步中,机器会分多次对图进行「降噪」,只是没有将每一次的结果用 Image Decoder 解码成图片,而是只将最后一次结果解码成照片。所以你使用 Stable Diffusion 的时候才不会像 Midjourney 那样看到生成的过程。
Image Information Creator
既然说到降噪,我们就来展开讲讲整个「降噪」的过程。
首先整个降噪的过程会在一个 Latent Space(潜空间)里进行,然后会进行多 Steps(步)的降噪,你可以对这个 Steps 进行调整,一般越多图片质量也会好,但时间也会越久。当然这个也跟模型有关,Stable Diffusion XL Turbo 就能 1 步出图,耗时不到 1 秒,而且生成的图片质量还很不错。如果我们将这一步过程可视化,类似是这样的(为了更好地解释,我将下方黑色的块都描述成图,本质上它不是图,只是一堆与图像相关的数据):
那 Denoise 里又发生了什么呢?下图是第一个 Denoise 过程的可视化:
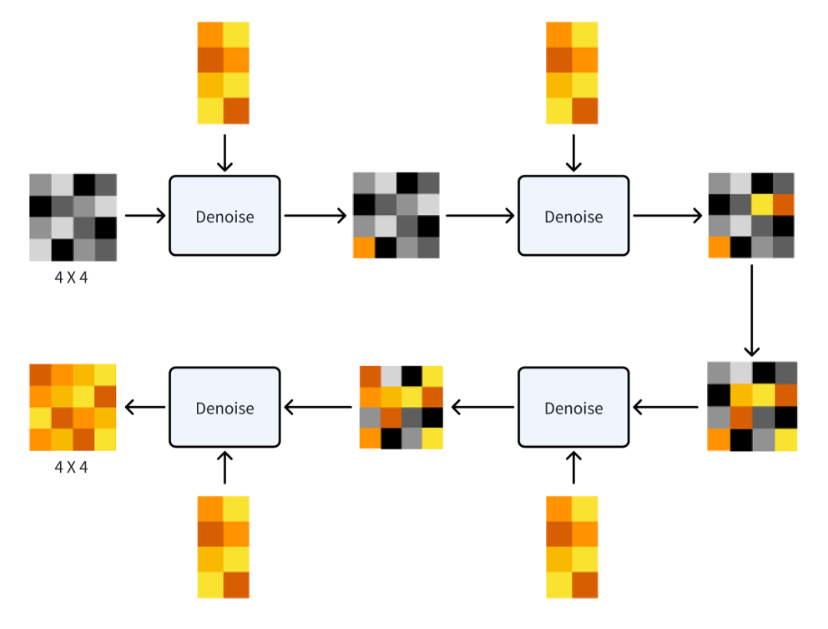
上图看上去很复杂,但不要恐惧,我们只要懂加减乘除就能理解这张图:

- 首先,在 Denoise 里有一个 Noise Predictor(噪音预测器),顾名思义,它就是能预测出随机图里包含什么噪音的模型。除了输入随机图和 Prompt 的词特征向量外,还需要输入当前的 Step 数。虽然在上面的可视化流程中,你会看到很多个 Denoise,但实际程序运行的是同一个 Denoise,所以需要将 Step 告知 Noise Predictor 让其知道正在进行哪一步的预测。
- 然后,我们先来看橙色的线,Noise Predictor 会使用随机图(比如一张4 X 4的图)和 Prompt 的词特征向量预测出一张噪声图 B。注意,这里不是根据预测输出实际的图,而是一张噪声图。换句话来说,Noise Predictor 是根据词向量预测这张随机图里有哪些不需要的噪声。如果拿前面的雕刻的例子来类比,它输出的是雕刻雕像所不需要的废料。于此同时,Noise Predictor 还会不使用 Prompt 的词特征向量预测出一张噪音图 C(也就是图中的蓝色线)。
💡 你可能好奇,为何我要高亮 4 X 4?回看完整的 Denoise 的流程,你会发现,开始的时候,随机图是 4 X 4,结果也是 4 X 4,这就意味着如果你想要改变最终生成图像的比例,或者是大小,你需要修改这个随机图的比例或大小,而不是通过 Prompt 下达调整的指令。用雕刻来类比,会很好理解,用 1 立方米的石头进行雕刻,不管雕刻师技艺有多好,都没法雕刻出一个高 10 米的雕像。它最多只能雕刻一个高 1 米的雕像。
- 接着,Denoise 会拿噪音图 B 和 C 相减得出图 D。我们用简单的数学解释下这张图是啥。首先,图 B 是用 Prompt 加随机图预测的噪声,简单理解,就包含了「根据 Prompt 预测的噪声」+「根据随机图预测的噪声」,而 C 则是「根据随机图预测的噪声」,B 减 C 就等于「根据 Prompt 预测的噪声」。
- 再之后,Denoise 会将 C 噪声放大,一般就是会乘以一个系数,这个系数在一些 Stable Diffusion 里会以CFG、CFG Scale 或者 Guidance Scale表示。接着再那这张放大后的图与噪声图 C 相加,得到图 E。这样做的原因是为了提高图片生成的准确性,所以通过乘以一个系数,来刻意提高「根据 Prompt 预测的噪声」的权重。如果没有这一步,生成的图片就跟 Prompt 没那么相关了。这个方法也被称为 Classifier Free Guidance(无分类引导法)。
- 最后,Denoise 会将图 A 减去图 E,得出一张新的图。也就是我前面提到的「雕刻」的过程,去掉不需要的噪声。
💡 如果你有用过 Stable Diffusion 的工具,你会发现 Prompt 的输入框有两个,一个是正向的,一个负向的。那负向的 Prompt 是如何生效的呢?用上述的数学方法,简单理解,当输入负向的 Prompt 的时候,也会生成一张噪声图 B2,但此时我们会用正向的 Prompt 生成的噪声图 B1 减去 B2 再减去 C 得出 D,那就意味着最终生成的图片会更加远离 B2,因为减掉了更多与 B2 相关的噪声。
Image Decoder
接着我们再来聊下 Latent Space(潜空间)。我在学习这个概念的时候,最大的疑惑就是为何要在潜空间里进行?而不是直接用图片进行去噪?
要解答这个问题,首先要理解什么是潜空间?
Latent Space(潜空间):潜在空间是指在机器学习和深度学习中,用于表示数据的低维空间。它是通过对原始数据进行编码和降维得到的一组潜在变量。潜在空间的维度通常比原始数据的维度低,因此可以提取出数据中最重要的特征和结构。
看上去很复杂,简单理解就是潜空间会将图片编码成一堆数字,同时对这些数字进行压缩。让我们通过可视化的方式看看这个过程:
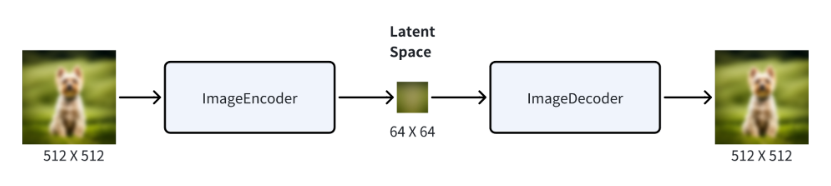
图片会先被一个 Image Encoder 编码成一组数据,并被压缩,如果用像素的角度来衡量这个数据压缩的效果,原图可能是一张 512 X 512 的图,压缩后变成了 64 X 64,数据极大地减少了,最后再使用 Image Decoder 还原即可。而这个 Encoder 加 Decoder 的组件,也被称为 Variational Auto Encoder(变分自编码器)简称 VAE 。所以这个 Image Decoder 在一些产品里,也叫 VAE Decoder。
那使用这个技术有什么好处和坏处呢?
好处:
- 首先当然是效率提升了非常多。使用 VAE 后,即使民用的 GPU 也能以相对较快的速度,完成降噪运算。同时训练模型的时间也会更短。
- 另外,潜在空间的维度通常比原始图像的维度低得多,这意味着它可以更有效地表示图像的特征。通过在潜在空间中进行操作和插值,可以对图像进行更精细的控制和编辑。这使得在生成图像时可以更好地控制图像的细节和风格,从而提高生成图像的质量和逼真度。
坏处:
- 经过编码,然后再将数据还原会导致一些数据丢失。而且加上潜在空间的维度较低,它可能无法完全捕捉原始数据中的所有细节和特征。最终导致还原的图片比较奇怪。
💡 为何 Stable Diffusion 生成的图片中,文字一般都很诡异?因为在这个过程中,一方面是文字的一些细节特征丢失了。另一方面,在预测噪音的时候,文字的预测与图像的预测相比,不那么连贯。举个例子,预测狗的特征是相对简单的,因为狗大概率有 2 个眼睛,眼睛下面是鼻子,它是连贯的。
Text Encoder
在最前面的流程中,我提到过,Text Encoder(文本编译器)会将你输入的 Prompt 编译成一个个的词特征向量。此步骤下会输出 77 个等长的向量,每个向量包含 768 个维度。这些向量里到底有什么用呢?
另外,还有一个更有趣的问题,当我们在 Prompt 里只输入 Dog,并没有在 Prompt 里加上狗的品种,那为何最后输出的狗是“约克夏”呢?要回答这些问题,我们需要先理解 Text Encoder 的实现。
目前 Stable Diffusion 常用的 Text Encoder 用的是 OpenAI 开源(opens in a new tab)的 CLIP 模型,全称为 Contrastive Language Image Pre-training(对比语言图像预训练)。我们照例先画个图:
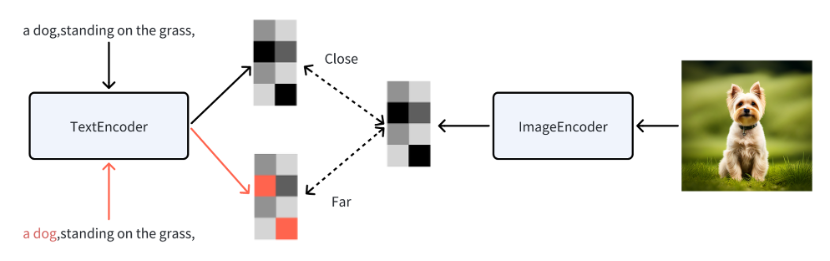
首先,这个 CLIP 也有一个 Text Encoder,会将文本转化为一个特征向量,然后它还有一个 Image Encoder 会将图片也转成各种特征向量。如果这两个向量越近,意味着这个描述,越接近图片的内容;反之越远,则越不相关。
OpenAI 使用了 4 亿组图片文本对,对此模型进行了训练,最后训练出来的 CLIP 模型效果如下图所示。当我们输入图片的描述时,CLIP 能判断出与这个描述最相近的图片是哪张。比如下图中第四行,描述是「一张约克夏狗的照片」,它与纵向第四张图最相关,相似度达到 0.31,与第一张书本的截图相似度只有 0.12。

我们回到 Stable Diffusion,在 Stable Diffusion 里,我们只使用了 CLIP 的 Text Encoder 的部分,因为它能将文本转化成对应文本的特征向量,并且这些特征向量与现实存在的图片会有相关性。
为何当我们输入 Dog 的时候,生成的图大概率是一只约克夏?因为 Text Encoder 将 Dog转化成 77 个等长的向量 Embedding 里会包含与 Dog 相关的一些特征和含义:
- 形态特征:向量表示可能会捕捉到 Dog 的形态特征,比如它的体型、头部的形状、四肢的位置等。这些特征可以帮助区分 Dog 与其他动物或物体。
- 视觉特征:向量表示可能会包含 Dog 的视觉特征,比如它的颜色、毛发、眼睛的形状等。这些特征可以帮助识别 Dog 的外观特点。
- 语义含义:向量表示可能会包含与 Dog 相关的语义含义,比如它是一种宠物、一种独立的动物、与人类有亲密关系等。这些含义可以帮助理解 Dog 在人类文化和社会中的角色和意义。
⚠️ 注意:因为模型有些地方具有不可解释性,所以实际上这些向量不一定包含这些特征,主要是为了更好地解释,所以我举了几个比较具象的例子。
最后,因为在 Stable Diffusion 里,只用到了 CLIP 的 Text Encoder 的部分,所以在一些产品里,这个又称为 CLIP Text Encoder,或者 CLIP Text Encode。
💡 为何使用 Stable Diffusion 或者 Midjourney 时,输入的 Prompt 不需要在意语法?以及大小写不明感呢?因为这些 Prompt 都会被 Text Encoder 转成特征向量,语法、大小写被转成特征向量后,都会是一串数字了,在没有对模型进行调整的情况下,这些都不太敏感了。
总结
感谢你看完这么长的 Stable Diffusion 基础(技术篇),在了解了这些技术之后,为我们下一篇该怎么写提示词,选择模型和采用器打好了基础。
