嗨,大家好!近期惊喜连连,多家大厂发布了性能出色的开源大语言模型,连”CloseAI”也开源了,实在令人惊叹!我打算做个实测对比:国内阿里千问团队新推出的 Qwen3-2507系列,和国外 OpenAI 团队开源的 GPT 系列,看看哪个大语言模型更适合我们个人用户在日常生活中使用。
Qwen3-2507系列:
Qwen3-Instruct-2507、Qwen3-Thinking-2507两大种类(其他量化版本就不一一统计)
| 模型型号 | 参数量 | 激活参数 | 上下文长度 | 总专家数 | 活跃专家数 |
|---|---|---|---|---|---|
| Qwen3-235B-A22B-Instruct-2507 | 235B(2350亿) | 22B(220亿) | 256k | 128 | 8 |
| Qwen3-235B-A22B-Thinking-2507 | 235B(2350亿) | 22B(220亿) | 256k | 128 | 8 |
| Qwen3-30B-A3B-Thinking-2507 | 30B(300亿) | 3B(30亿) | 256k | 128 | 8 |
| Qwen3-30B-A3B-Instruct-2507 | 30B(300亿) | 3B(30亿) | 256k | 128 | 8 |
| Qwen3-4B-Thinking-2507 | 4B | – | 256k | – | |
| Qwen3-4B-Instruct-2507 | 4B | – | 256k | – |
Qwen3-Instruct-2507具有以下特点:
- 一般能力有显著提高,包括遵循指令、逻辑推理、文本理解、数学、科学、编码和工具使用。
- 跨多种语言的长尾知识覆盖率大幅提升。
- 在主观和开放式任务中明显更好地与用户偏好保持一致,从而能够获得更多有用的回应和更高质量的文本生成。
- 增强了256K长上下文理解能力,可扩展至1M。
Qwen3-Thinking-2507具有以下特点:
- 在推理任务上的性能显著提高,包括逻辑推理、数学、科学、编码和通常需要人类专业知识的学术基准——在开源思维模型中取得最先进的成果。
- 明显更好的通用能力,例如指令遵循、工具使用、文本生成和与人类偏好的一致性。
- 增强256K长上下文理解能力,可扩展至1M。
MoE(混合专家)模型架构,类型都是因果语言模型(Causal Language Models, CLM)属于自回归模型的一种,其核心目标是基于历史上下文预测下一个标记的概率分布。
总结一下基准评分分数都很惊人!
GPT-OSS系列:
gpt-oss-120b、gpt-oss-20b总共就两款:
| 模型型号 | 参数量 | 激活参数 | 上下文长度 | 总专家数 | 活跃专家数 |
|---|---|---|---|---|---|
| gpt-oss-120b | 117B(1170亿) | 5.1B(51亿) | 128k | 128 | 4 |
| gpt-oss-20b | 21B(210亿) | 3.6B(36亿) | 128k | 32 | 4 |
GPT-OSS具有以下特点:
- **宽松的 Apache 2.0 许可证:**自由构建,不受版权限制或专利风险 – 非常适合实验、定制和商业部署。
- **可配置的推理力度:**根据您的具体用例和延迟需求轻松调整推理力度(低、中、高)。
- **完整的思路链:**完全访问模型的推理过程,从而更轻松地进行调试并增强对输出的信任。它不打算向最终用户展示。
- **可微调:**通过参数微调完全根据您的特定用例定制模型。
- **Agentic 功能:**使用模型的本机功能进行函数调用、网页浏览、Python 代码解释器和结构化输出。
- **原生 MXFP4 量化:**模型使用原生 MXFP4 精度针对 MoE 层进行训练,使其在单个 H100 GPU 上运行,并且模型在 16GB 内存内运行。
另外,如果原生应用GPT-OSS系列模型需要搭载OpenAI的Harmoney格式,后来我仔细看看了模型自带的模板文件,多出了一个channel字段,应该是为模型与模型之间通讯准备的。还有个细节,GPT-OSS系列模型有三种级别的推理水平,分别为:低、中、高,在systemprompt中填入Reasoning: low or medium or high则会启动不同的推理等级。
总结一下基准评分分数也很惊人!
以上是两大大厂最新开源的高性能大语言模型的特点和参数,接下来我们开始一些非严谨性测试吧!
KunAvatar+ollama启动!
为了这次测试,我们特地开发了kunlab的升级版kunavatar!依然是基于ollama推理引擎上运行的一套功能齐全的桌面客户端,支持MCP工具调用、记忆总结注入、智能体等等。
测试模型:GPT-OSS:20B和qwen3:30b-a3b-thinking-2507 都是Q4量化版本
推理引擎:Ollama
自然语言类(类比与隐喻):
问题 (理解类比): 时间就是金钱’这句话是什么意思?请从至少两个不同角度解释其含义。
测试目的: 看AI是否能解释这个常见的隐喻,理解时间和金钱在“稀缺性”、“可衡量性”和“价值”上的共同点。
GPT-OSS:20B:


qwen3:30b-a3b-thinking-2507


接下来有请我们的Gemini2.5pro作为评分专家,先说结论:
GPT-OSS 模型:得分:8.0 / 10
Qwen3 模型:得分:9.5 / 10
再说评估细节:
评估问题:“‘时间就是金钱’这句话是什么意思?请从至少两个不同角度解释其含义。”
核心测试点:抽象思维、逻辑结构、观点深度、举例能力。
1. GPT-OSS 模型
得分:8.0 / 10
优点分析:
- 结构化能力 (10/10): 回答的结构堪称典范。使用主标题、副标题、项目符号、引用块和总结表格,将复杂的概念分解得井井有条,阅读体验极佳。
- 内容详实度 (9/10): 内容非常丰富,从经济学的“机会成本”到个人成长的“自我效能”,覆盖面很广,并且都给出了合理的解释。
- 举例质量 (8/10): 例子(如软件工程师、AI客服)都非常贴切,能够很好地支撑其论点,特别是量化的例子让概念更具体。
缺点分析:
- 观点深度与区分度 (5/10): 这是其主要失分点。模型提出的两个角度——“经济/商业视角”和“个人成长/自我管理视角”——本质上都是在同一个经济学框架下的思考。第二个角度只是将第一个角度的“企业经营逻辑”应用到了“个人经营逻辑”上,核心都是“投入时间换取未来回报”。它没有跳出“时间是一种可投资资产”这个核心范式,缺乏对这句话本身带来的负面影响或社会文化层面的批判。
2. Qwen3 模型
得分:9.5 / 10
优点分析:
- 观点深度与区分度 (10/10): 这是它最出彩的地方。模型提出的两个角度——“经济效率视角” 和 “社会文化与人的异化视角”——构成了真正意义上的对立和辩证。它不仅解释了“是什么”(what),还深入探讨了“导致了什么”(so what)。后者触及了现代性的核心问题:人的物化、时间焦虑和非经济价值的丧失。这体现了极强的抽象和批判性思维。
- 举例的冲击力 (9.5/10): 例子(如开会成本的具体计算、996文化、用冥想APP给发呆计时)非常犀利,直指问题核心。最后用程序员的例子来总结两个视角的冲突,极具说服力。
- 逻辑与综合能力 (10/10): 模型的逻辑链非常清晰。它先分别阐述两个视角,然后用一个表格和一个综合案例将两者进行辩证统一,最后在结论中升华主旨。整个回答一气呵成,思想深度逐层递进。
- 思维过程透明化: 它思考了不同角度的可能性(历史、哲学),并最终选择了对比最强烈的两个角度。
总结对比
| 评估维度 | GPT-OSS | Qwen3 | 优胜者 |
| 结构清晰度 | ★★★★★ | ★★★★★ | 平手 |
| 观点区分度 | ★★★☆☆ | ★★★★★ | Qwen3 |
| 思想深度 | ★★★☆☆ | ★★★★★ | Qwen3 |
| 举例贴切性 | ★★★★☆ | ★★★★★ | Qwen3 |
| 抽象与批判性 | ★★☆☆☆ | ★★★★★ | Qwen3 |
| 实用性 | ★★★★★ | ★★★☆☆ | GPT-OSS |
代码类测试:
###提示词
**快速打地鼠 (Whac-a-Mole)**
**任务描述:**
创建一个简单的“打地鼠”网页游戏。游戏开始后,地鼠会从不同的洞里随机钻出来,玩家需要快速点击它得分。
**核心功能要求:**
1. **游戏面板 (Game Board):**
- 使用 HTML 和 CSS 创建一个 3x3 的网格作为“地洞”。
- 每个地洞平时是空的,地鼠出现时会改变外观。
2. **地鼠随机出现 (Random Mole):**
- 使用 JavaScript 每隔一段时间(例如 1 秒)随机选择一个地洞。
- 让“地鼠”(可以是一个图片或一个不同的背景色)在这个选中的洞里“出现”。
3. **地鼠自动消失 (Disappear Automatically):**
- 每次地鼠出现后,它应该在短暂的停留后(例如 800 毫秒)自动消失。
4. **点击得分 (Click to Score):**
- 玩家点击“出现”的地鼠时,分数加 1。
- 需要在页面上实时显示当前分数。
- 为防止连续点击得分,点击一次后,地鼠应立即算作“被打到”并消失。
5. **游戏循环 (Game Loop):**
- 整个“出现-消失”的过程需要不断重复,让游戏持续进行。GPT-OSS:20B:
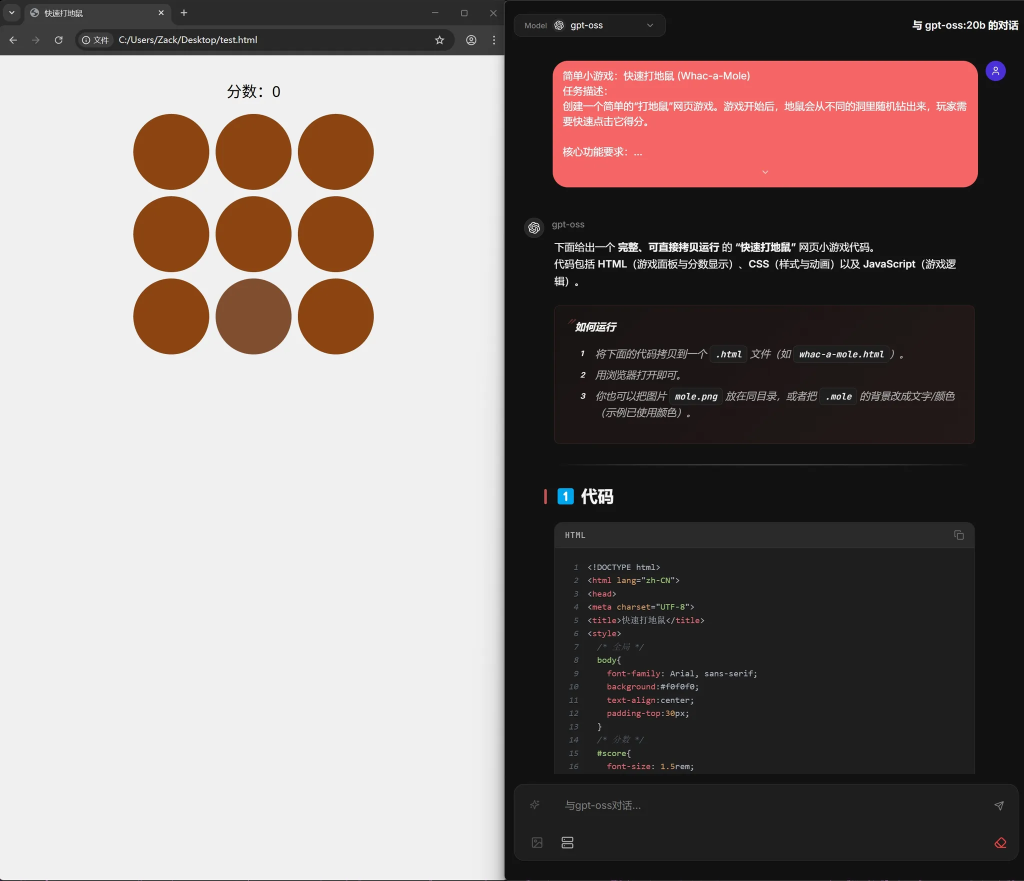
游戏质量单看UI就知道了吧,运行也有很多,总之不太行。代码部分有少许语法错误。总共108行,生成时间67秒。
qwen3:30b-a3b-thinking-2507
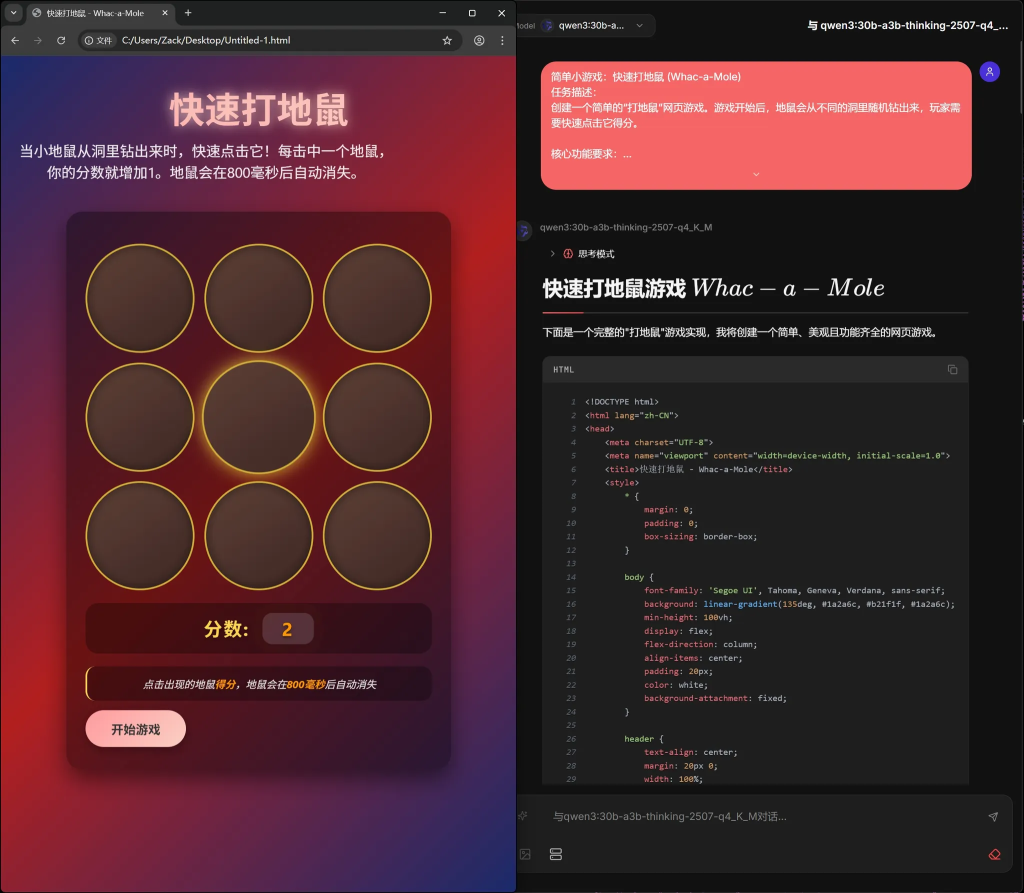
游戏质量还可以,可以运行,游戏逻辑也没有问题。代码部分只有些少许语法错误,稍微手动修改了一下。总共466行,生成时间335秒。
工具调用测试:
推荐一个MCP托管平台:https://smithery.ai
测试MCP服务器与工具:Supadata: Web & Video data API for makers
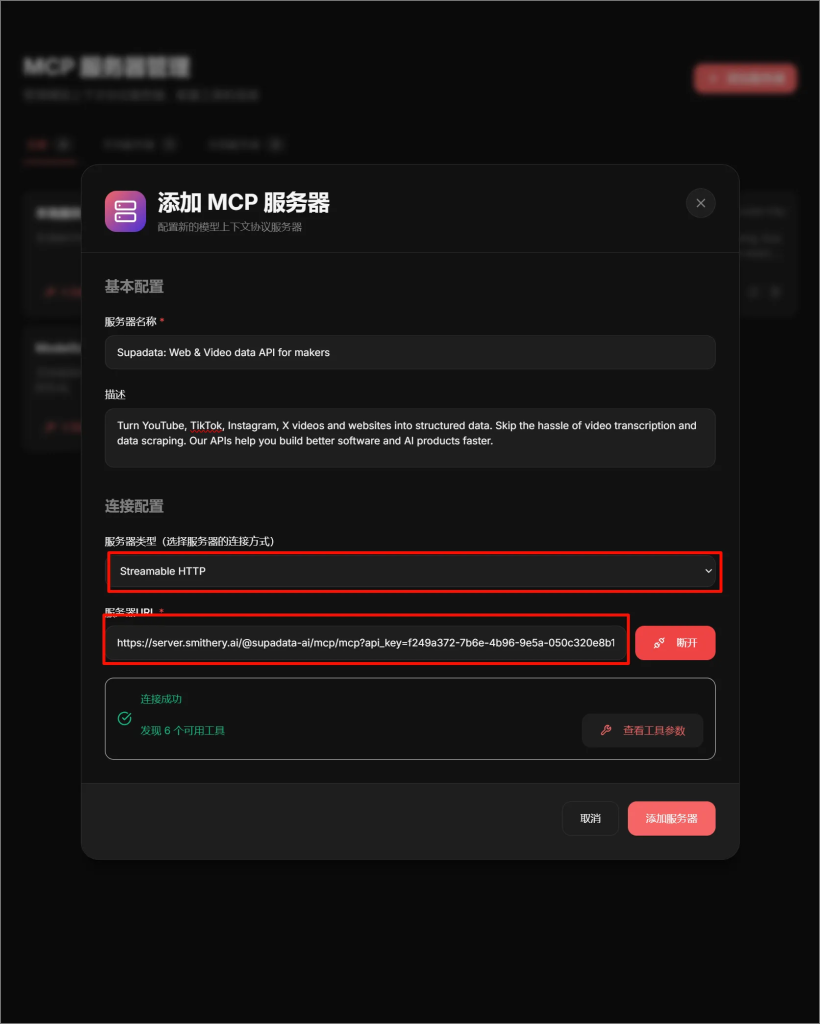
我们在kunavatar的MCP管理模块点击添加服务器按钮,会跳出弹窗,然后选择服务器类型为streamablehttp,在MCP托管平台中获取到服务器URL并填写进输入框,点击连接按钮就能获取到工具列表。(在创建MCP服务器过程中无需输入任何指令)
GPT-OSS:20B:

这个技术博主我非常喜欢的,所以这次试试他的视频内容。可能因为工具返回的结果没有视频标题的,只有视频字幕,导致视频标题是完全瞎编的,其余的视频内容基本是对的。
qwen3:30b-a3b-thinking-2507

Qwen3提取到了视频中的核心亮点,行业争议这一块,但是GPT模型没有提取出来,这是为什么呢?工具返回了2000多行,我仔细看了下很多内容都是正确的。
总结:
Qwen3 模型的性能表现非常突出,相较以往各类开源模型都展现出更出色的使用体验。值得一提的是,本次测试所用的模型系统参数均保持原始状态,未做任何调整,也未设置特殊的系统提示词,这使其在本地部署场景中,对普通用户的日常使用需求具有极高的适配性。然后就是OpenAI 这次开源的 GPT-OSS 无疑具有里程碑意义,其开放姿态已然清晰可见。不过从市场反响来看,这一举措似乎让扎克伯格此前的相关布局略显尴尬。
最后来个小推广:欢迎大家体验我们开源的 kunavatar 产品!目前它仅支持 ollama 推理引擎,桌面客户端也存在一定限制,暂时只提供 Windows 版本。不过在私有部署方面,它可是相当便捷 —— 基本上只需几行代码,就能快速运行起来啦~。