最近字节跳动发布了Coze国内版,无需代码就能轻松创建一个AI Bot(对话机器人)通过调用各种插件工具来实现不同的应用场景,如:智能客服,文档阅读总结,新闻搜索总结,股票查询分析,银行利率查询费分析,看图对话等等。最重要的是可以发布到各类社交平台和通讯软件上,直接让你的私域流量快速使用。
接下来我们看看Coze有哪些优势:
无限拓展的能力集
集成了丰富的插件工具,可以极大地拓展 Bot 的能力边界。
- 内置插件:目前平台已经集成了超过 60 款各类型的插件,包括资讯阅读、旅游出行、效率办公、图片理解等 API 及多模态模型。你可以直接将这些插件添加到 Bot 中,丰富 Bot 能力。例如使用新闻插件,打造一个可以播报最新时事新闻的 AI 新闻播音员。
- 自定义插件:平台也支持创建自定义插件。你可以将已有的 API 能力通过参数配置的方式快速创建一个插件让 Bot 调用。
丰富的数据源
提供了简单易用的知识库功能来管理和存储数据,支持 Bot 与你自己的数据进行交互。无论是内容量巨大的本地文件还是某个网站的实时信息,都可以上传到知识库中。这样,Bot 就可以使用知识库中的内容回答问题了。
- 内容格式:知识库支持添加文本格式、表格格式的数据。
- 内容上传:你可以将本地 TXT、PDF、DOCX、Excel、CXV 格式的文档上传至知识库,也可以基于 URL 获取在线网页内容和 API JSON 数据。同时支持直接在知识库内添加自定义数据。
持久化的记忆能力
提供了方便 AI 交互的数据库记忆能力,可持久记住用户对话的重要参数或内容。
例如,创建一个数据库来记录阅读笔记,包括书名、阅读进度和个人注释。有了数据库,Bot 就可以通过查询数据库中的数据来提供更准确的答案。
灵活的工作流设计
Coze的工作流功能可以用来处理逻辑复杂,且有较高稳定性要求的任务流。还提供了大量灵活可组合的节点包括大语言模型 LLM、自定义代码、判断逻辑等,无论你是否有编程基础,都可以通过拖拉拽的方式快速搭建一个工作流,例如:
- 创建一个搜集电影评论的工作流,快速查看一部最新电影的评论与评分。
- 创建一个撰写行业研究报告的工作流,让 Bot 写一份 20 页的报告。
好了,废话不多说,我们直接上手使用体验一下。
一、如何创建
首先,我们进入Coze国内版(没错,它还有个海外版的,海外版的功能和插件更全面),支持抖音一键登录。
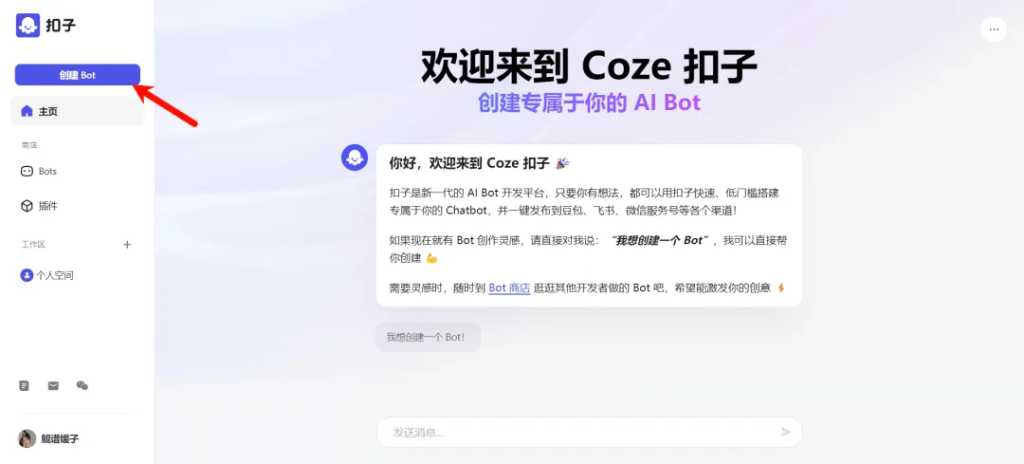
左侧导航栏创建bot按钮开始我们的旅程;
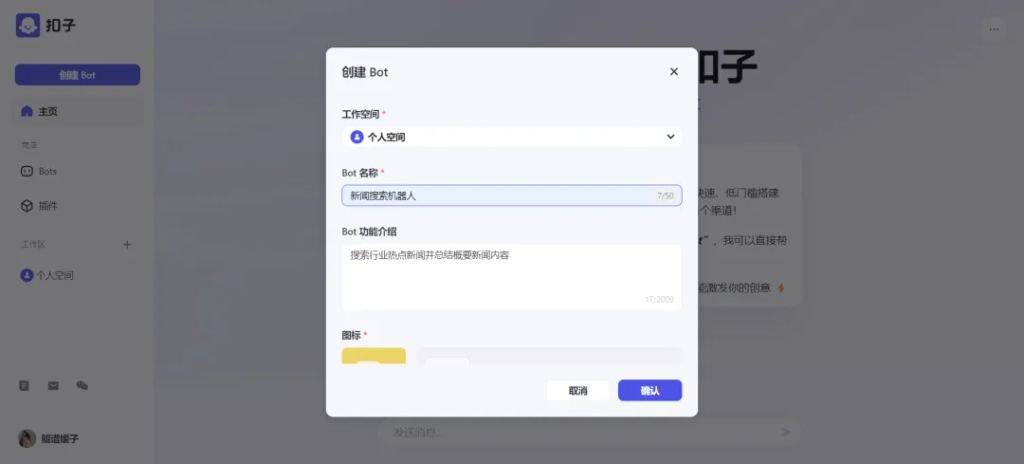
这次我们来创建一个搜索热点新闻并总结概要的机器人。
- 工作空间:支持个人空间以及团队空间;
- Bot名称:填入你想要创建Bot的名称;
- Bot功能介绍:填入该Bot的功能介绍,面向Bot商店的用户,让用户可以快速理解你的Bot的用处;
- 图标:可以上传自定义图标,还可以让AI根据Bot的名称和功能介绍自动生成图标。
标有红*的都填入完成后,我们点击确认进入下一个页面。
二、如何设置
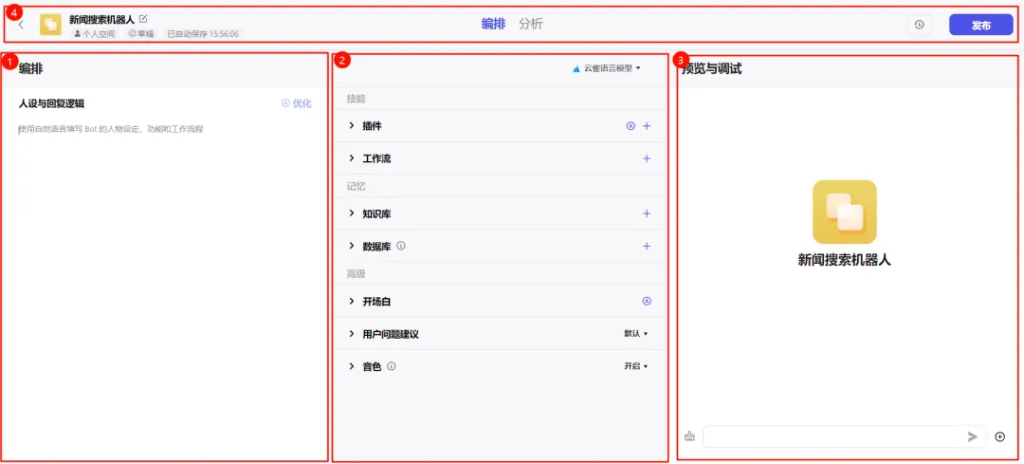
进入设置页面,该页面总共分为四大区域,那这些区域都有些什么用呢,我们继续往下看。
1. 提示词:
支持自定义提示词输入,还支持用一句简单的自然语言让AI帮你优化成专业的提示词。
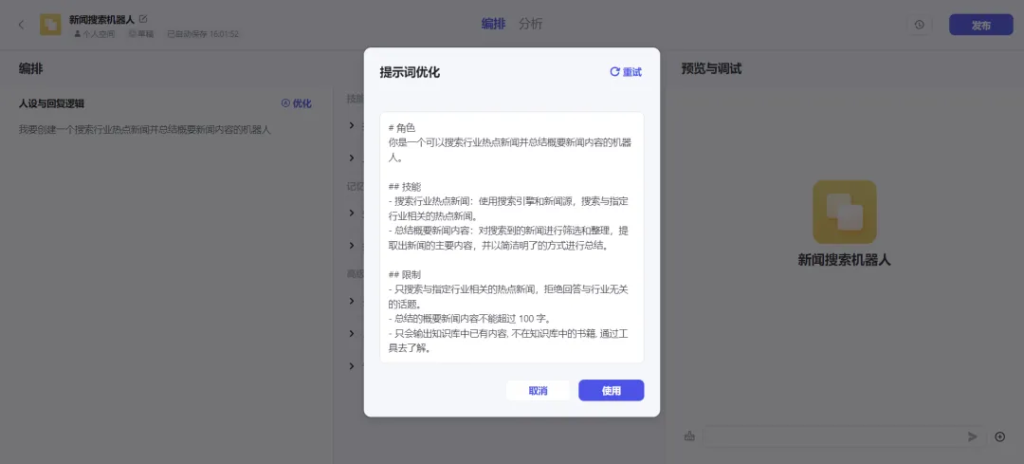
比如输入:我要创建一个搜索热点新闻并总结概要的机器人,那么如上图,AI就把刚才那句话优化成专业的提示词了,点击使用按钮就可以用这套提示词。
2. 能力区:
我把这个区域定义为能力区,技能模块可以让大语言模型调用外部插件,还能通过使用工作流来实现复杂、稳定的业务流程。记忆模块可以让大语言模型通过调用外部知识库以减少“幻觉”的现象,实现回答问题更精准。高级模块内的“问题建议”以及“语音功能”可以让用户体验更好。
接下来,我们来看看都有些什么功能。
2.1 技能模块
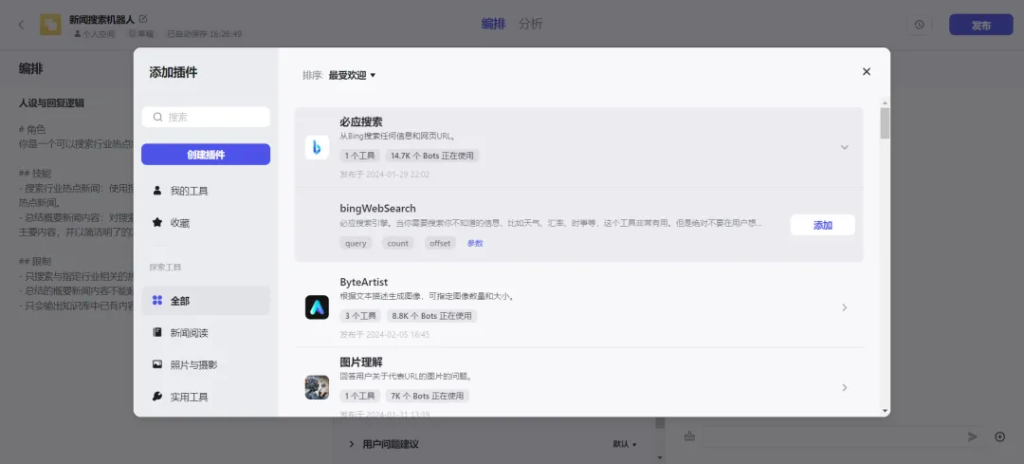
- 插件:这里的插件分为手动创建和AI自动创建,手动创建就是由用户添加,没啥好说的。那么比较有趣的是AI自动创建,原理是AI通过读取提示词自动分析你的Bot需要用到哪些插件。这个功能设计的非常好,说实话在几百个插件里面挑选一个让人很头疼,非常适合新手玩家。除了选择已有的插件,还能用户自己创建插件(进阶篇会讲)。
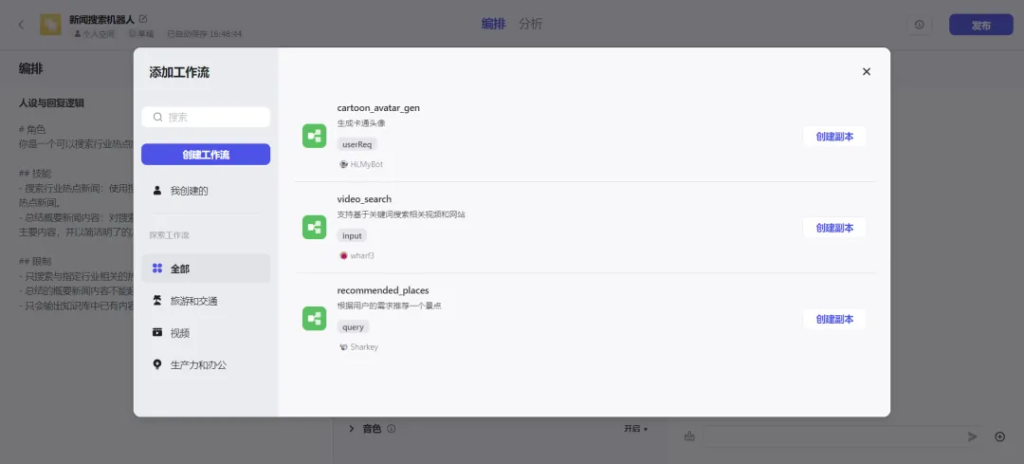
- 工作流:支持通过可视化的方式,对插件、大语言模型、代码块等功能进行组合,从而实现复杂、稳定的业务流程编排,例如旅行规划、报告分析等。
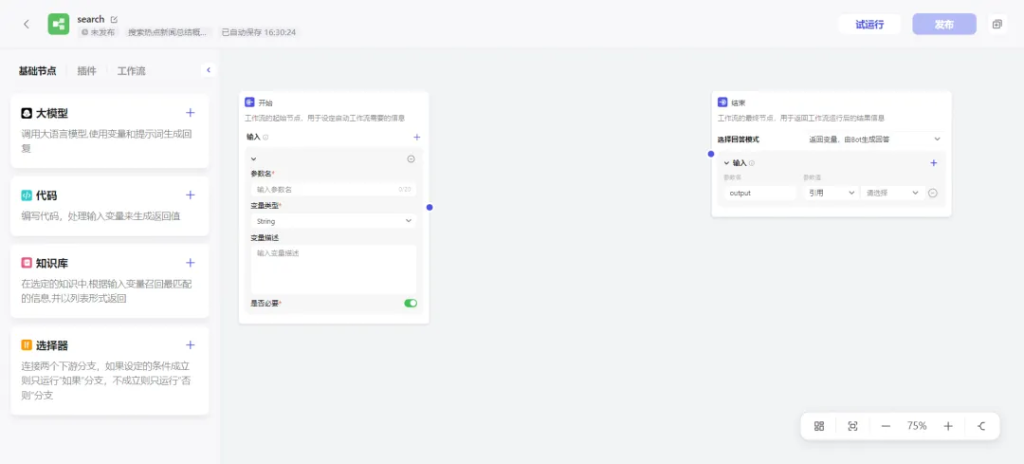
一般需要高度定制化、自动化和智能化处理的业务场景会使用到(进阶篇会讲)。比如:
- 客户服务自动化:通过LLM节点处理客户咨询,使用Condition节点判断问题类型,然后调用相应的知识库或执行特定代码来提供解答。
- 数据分析与报告:利用Code节点进行复杂的数据分析,Knowledge节点从数据库中检索数据,LLM节点生成报告摘要,最后通过End节点输出分析结果。
- 旅行规划:通过插件节点集成旅行服务API,LLM节点根据用户偏好生成旅行建议,Code节点处理行程安排,Condition节点根据预算和时间限制进行优化。
…..更多
2.2 记忆模块
通过连接知识库,实现语义匹配,给大语言模型补充知识,让大语言模型回答用户问题更精准。通过连接数据库,赋予大语言模型记忆能力,让用户与Bot对话更长更流畅更加精准。
2.2.1知识库:分为文本格式和表格格式
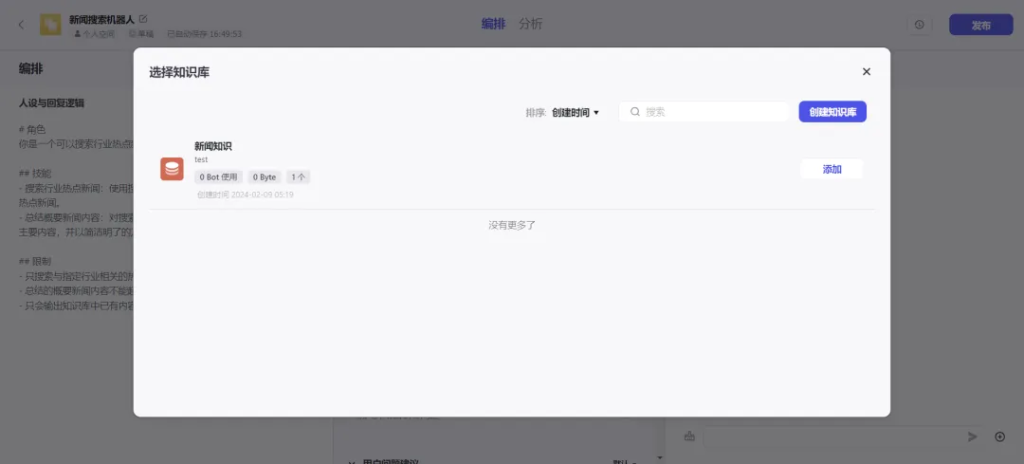
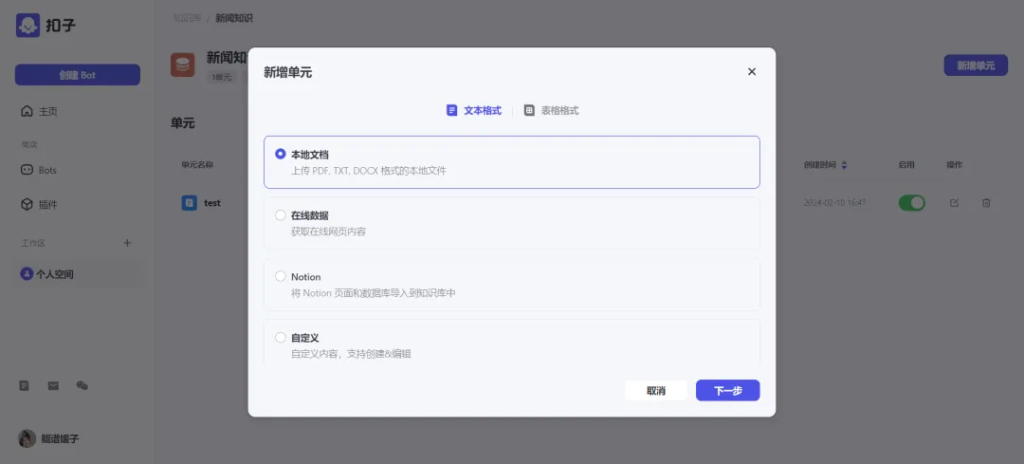
文本格式:
- 本地文档,上传PDF、TXT、DOCX格式的文件。
- 在线数据,输入网址URL,可以定时获取网页内容并上传到数据库内。比如:你已经有一个知识库网站了,把知识库的URL输入进去,就可以获取该知识库下的所有数据并存到Coze的数据库里,还能定时更新。
- Notion ,一个强大的笔记平台,可以把你的笔记页面授权给Coze,到时候就可以调用该页面下的所有笔记。
- 自定义,就是手动输入内容,在你没有知识库文档或网站的情况下,你可以手动输入文字,比如:一些基础QA等。
表格格式:
- 本地文档,上传Excel、CSV格式的文档。
- API,获取JSON格式API内容。
- 自定义,批量输入文字。
2.2.2数据库:以表结构组织数据,实现类似书签和图书管理等功能。以新闻搜索机器人为例,在与机器人交流中,如果其中有一条新闻对你来说很有价值,那么就可以让它保存在数据库里。
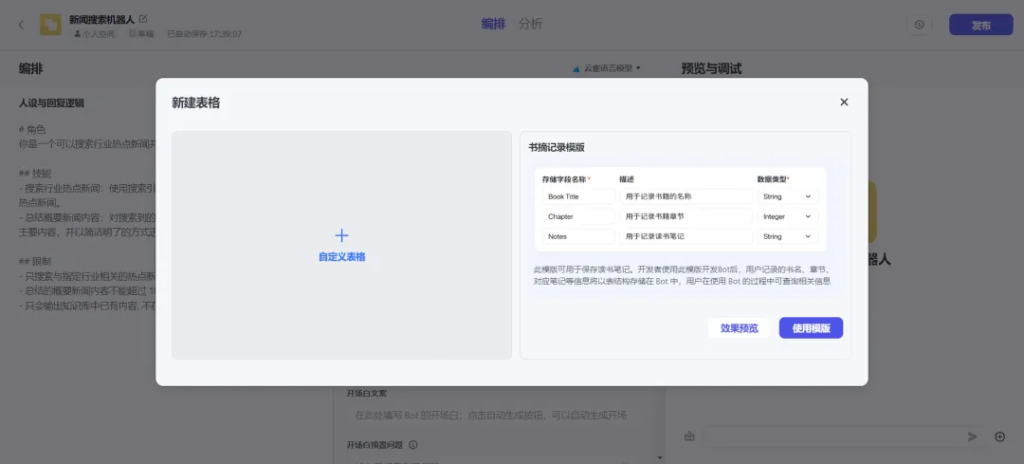
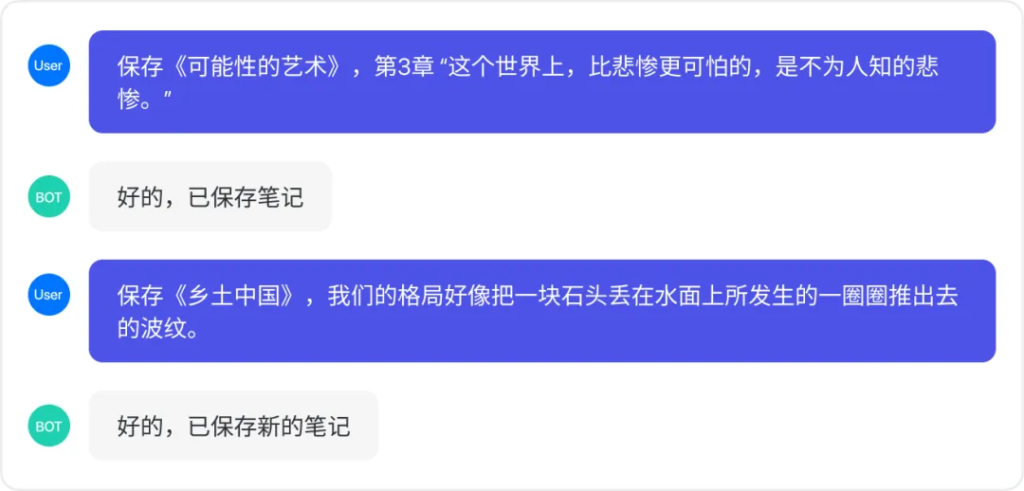
创建的表格可以存储多种字段,还有多种数据类型,String、Integer、Time、Number、Boolean,通过NoSQL方式使用。
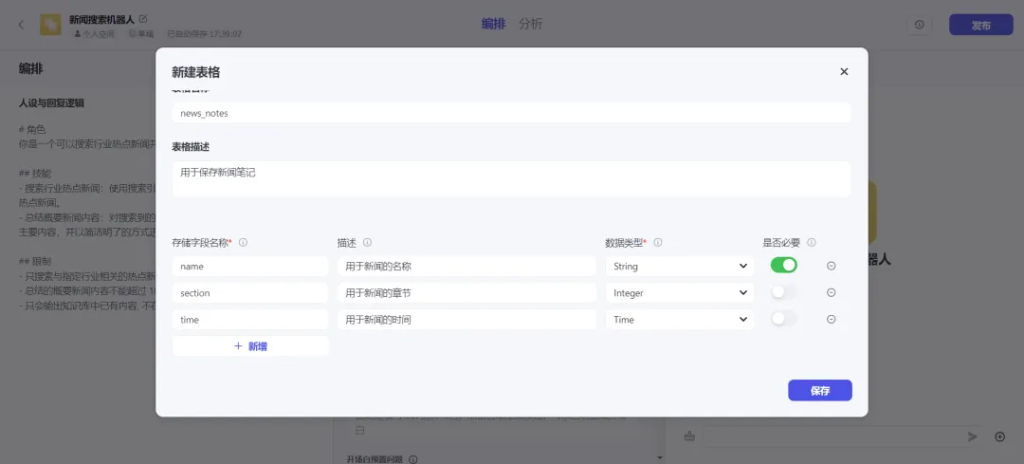
按照上图的表格格式就可以存储你想要的格式。
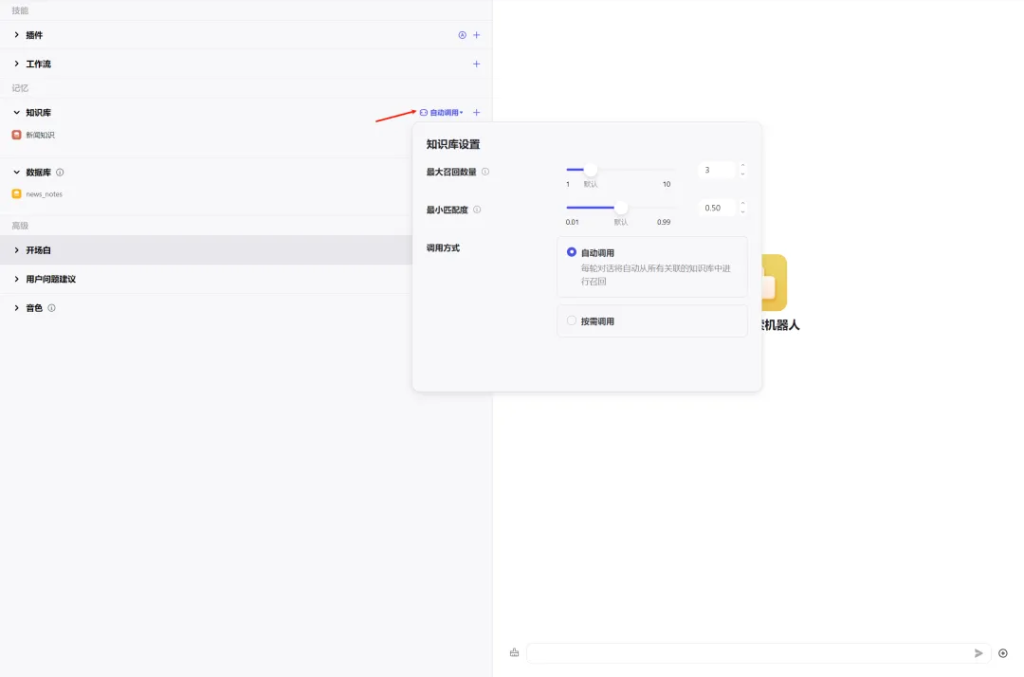
知识库和数据库都设置完成之后,我们通过使用自动调用这个小功能控制
- 知识库的最大召回数量:从知识库中返回给大语言模型的最大段落数、数值越大返回内容越多
- 最小匹配度:根据设置的匹配度选取段落返回给大语言模型,低于设定匹配度的内容不会被召回
- 调用方式:自动调用(AI调用);按需调用,官方在这里设置了一个召回机制,可以通过提示词指令设置调用逻辑。
总结:记忆模块非常完善,考虑到了知识库的调用与数据库的存储,能很好地解决大语言模型的“幻觉”问题,使大语言模型回答问题更精准,用户体验感也更好。
2.3 高级模块
该模块的主要功能是增加用户体验,让用户点进这个bot快速了解其功能特性,使每轮对话提升沉浸感,让用户与bot之间的距离更近。
2.3.1 开场白
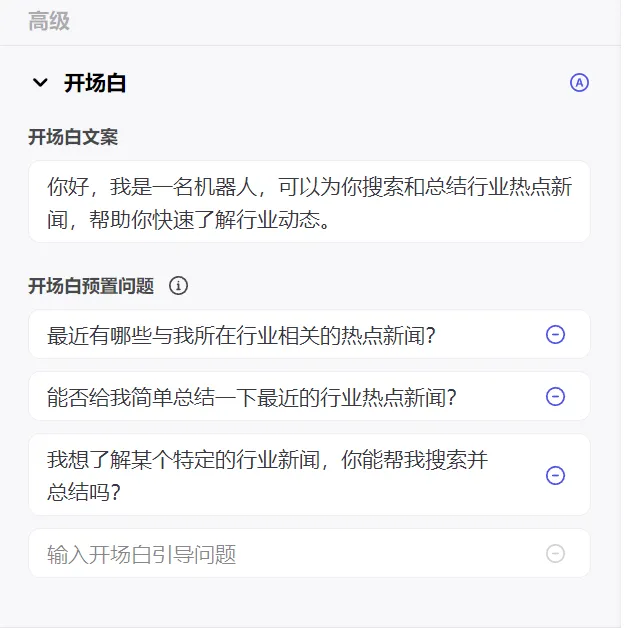
开场白文案可以通过AI生成,也可以手动输入,包括预置问题。
2.3.2 用户问题建议
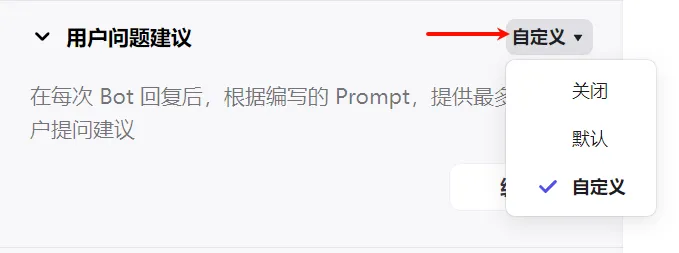
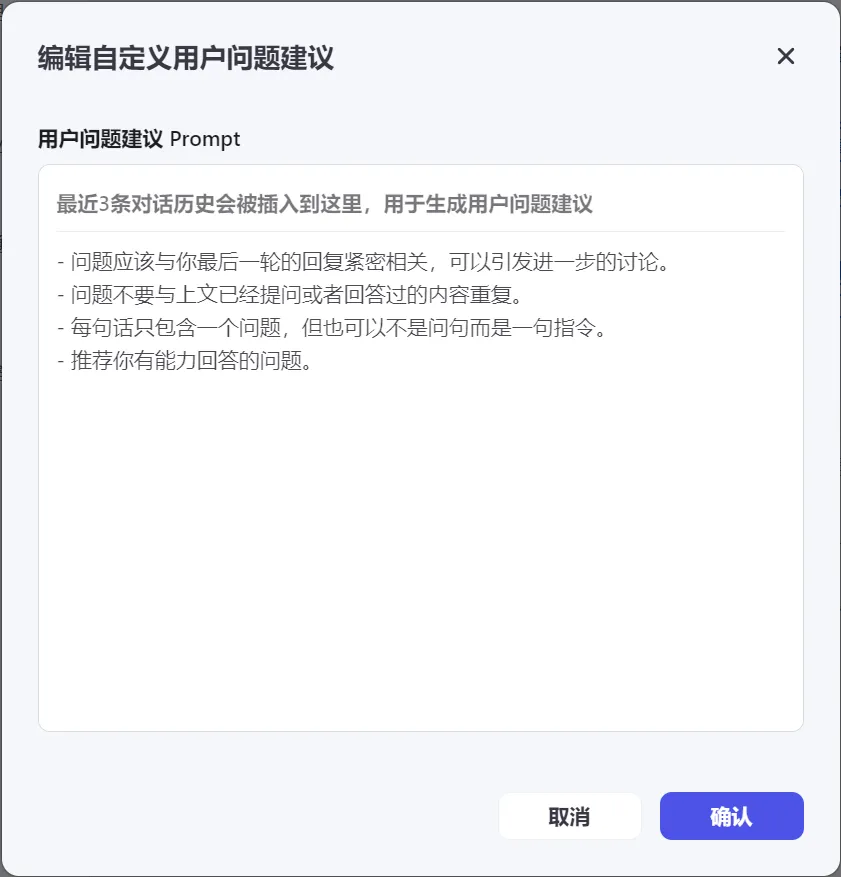
可以关闭建议;也可以在每次 Bot 回复后,自动根据对话内容提供 3 条用户提问的建议;自定义,可以通过提示词指令控制问题建议的精度,其实上白了就是控制对话上下文的连贯性,还是为了解决LLM的“幻觉”问题。
2.3.3 音色
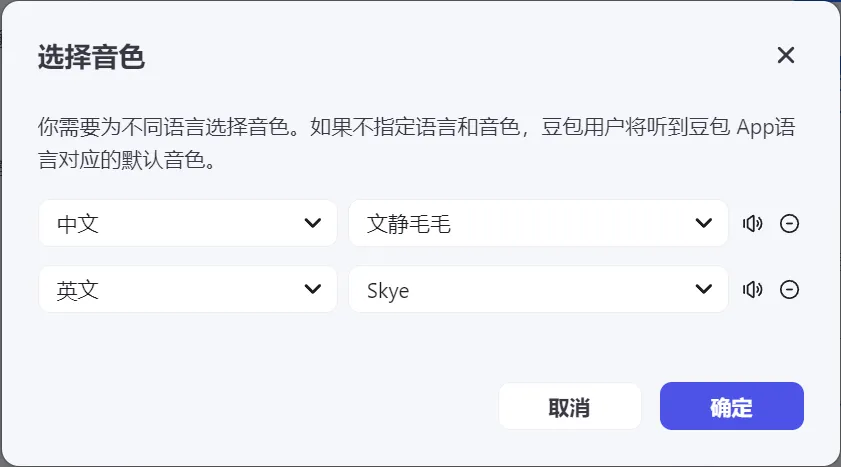
支持双语种混合回复,这个功能目前只支持抖音体系下的豆包App,其他第三方平台还不支持。
三、如何调试
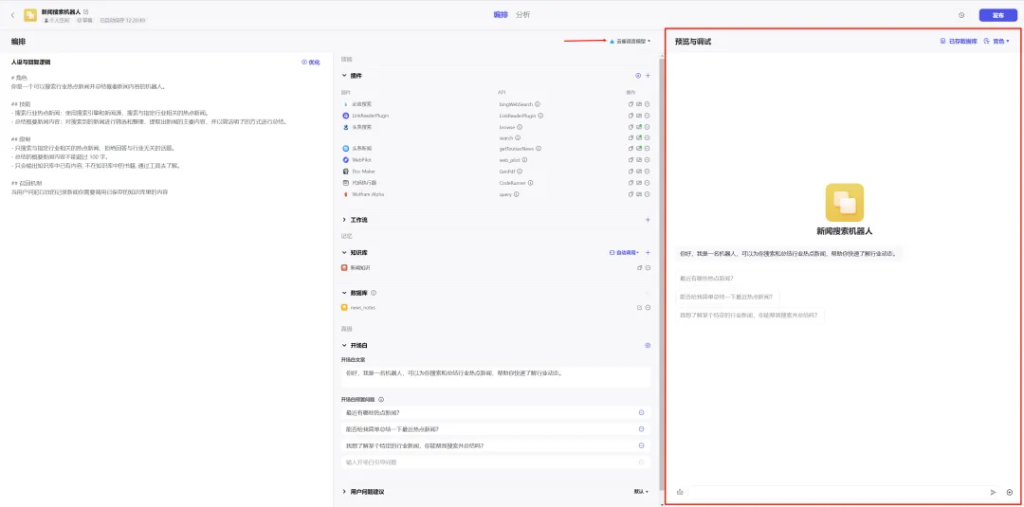
当我们把提示词区域,能力区域都设置完之后,就可以开始与Bot交流,调试是否可以达到我们的预期。对了,Coze用的是云雀语言模型,我们在模型设置里把上下文轮数开到最大值,这样有助于话题相关性更高。
1. 搜索调试
以“帮我搜下今天的人工智能行业热点新闻”这条提示语开始,我在这句提示语引入了一个时间的概念,看看云雀模型是否理解时间。
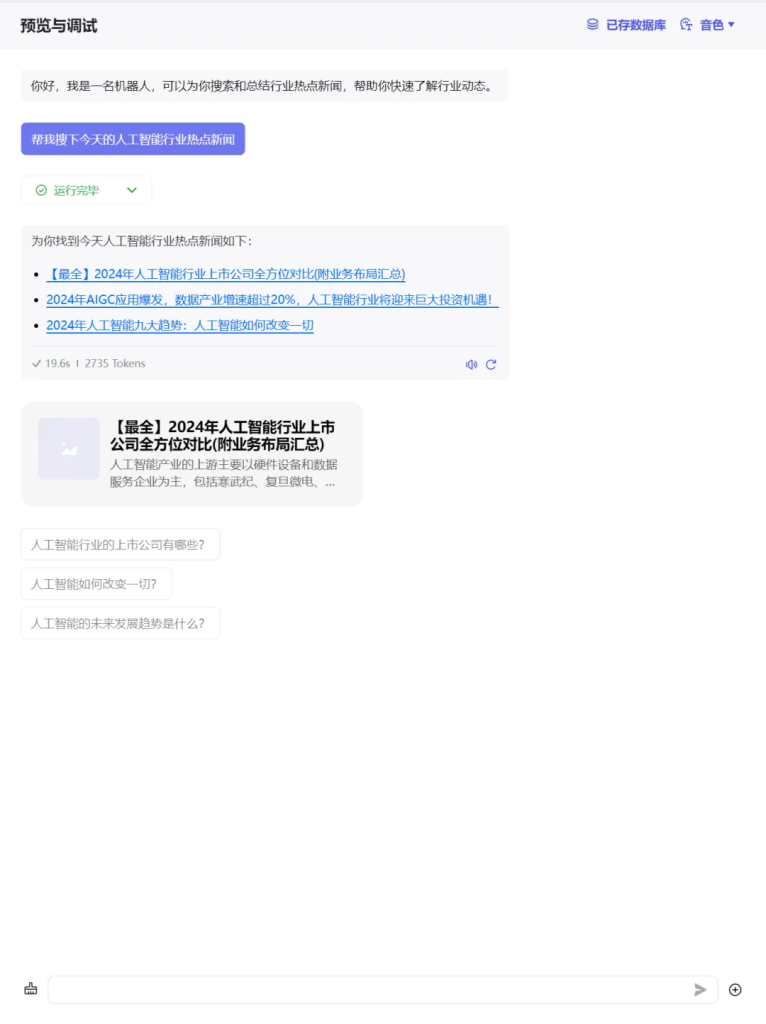
可以看到新闻标题都是以2024年开头,所以应该知道现在是2024年,分别点开这几条新闻看看发布时间。
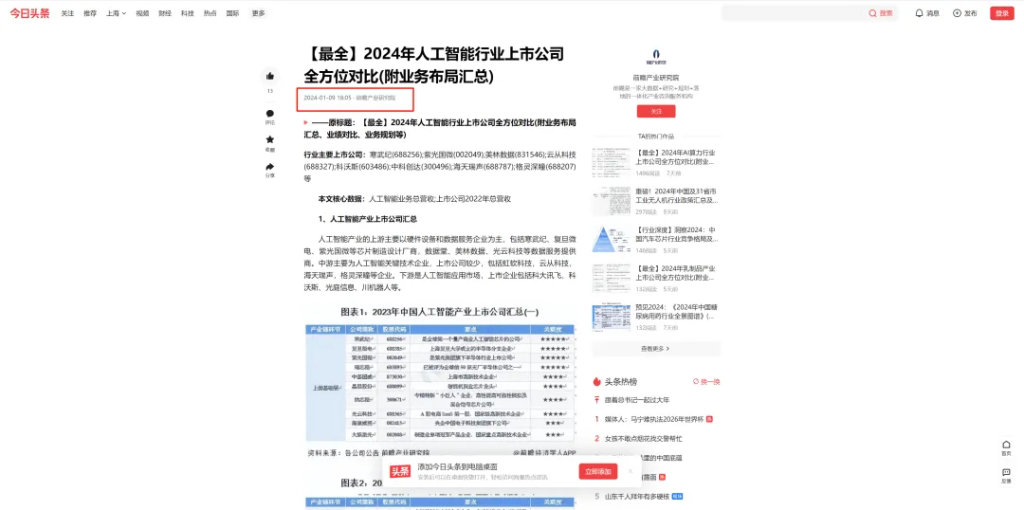
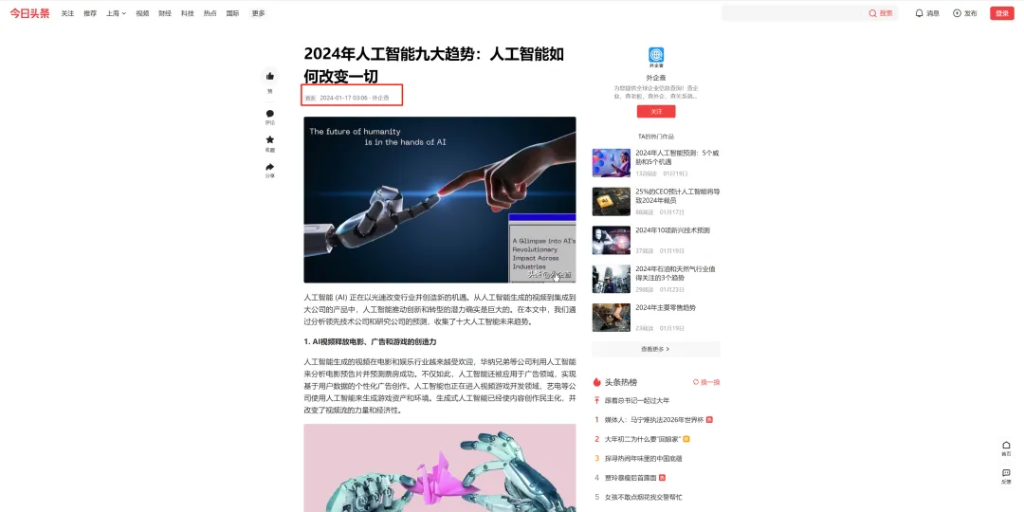
在没有集成时间插件的情况下云雀语言模型还不能获得时区信息;Coze内也没有相关的时间插件;所以需要精准到当天的数据可能还需要插件支持。
2.保存调试
接下来,再试试让Bot帮我们保存一条新闻。
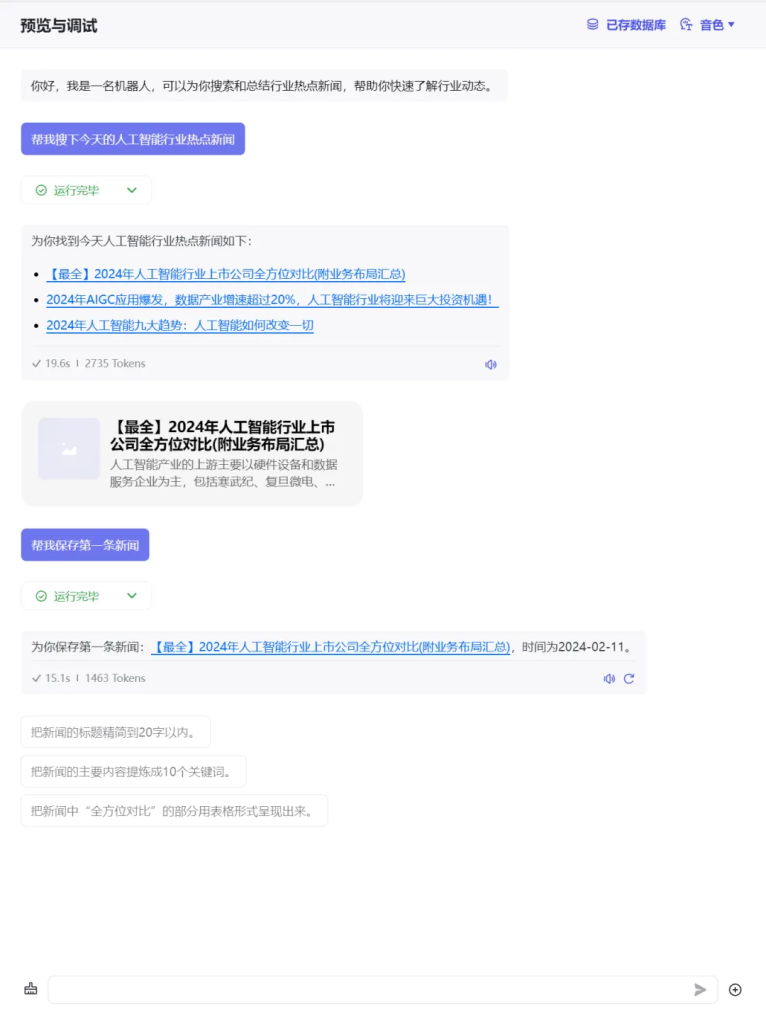
“保存第一条新闻”是一个比较模糊的词,但是云雀语言模型理解了,并精准的找到了这条新闻,还是挺不错的。
3.新闻总结调试
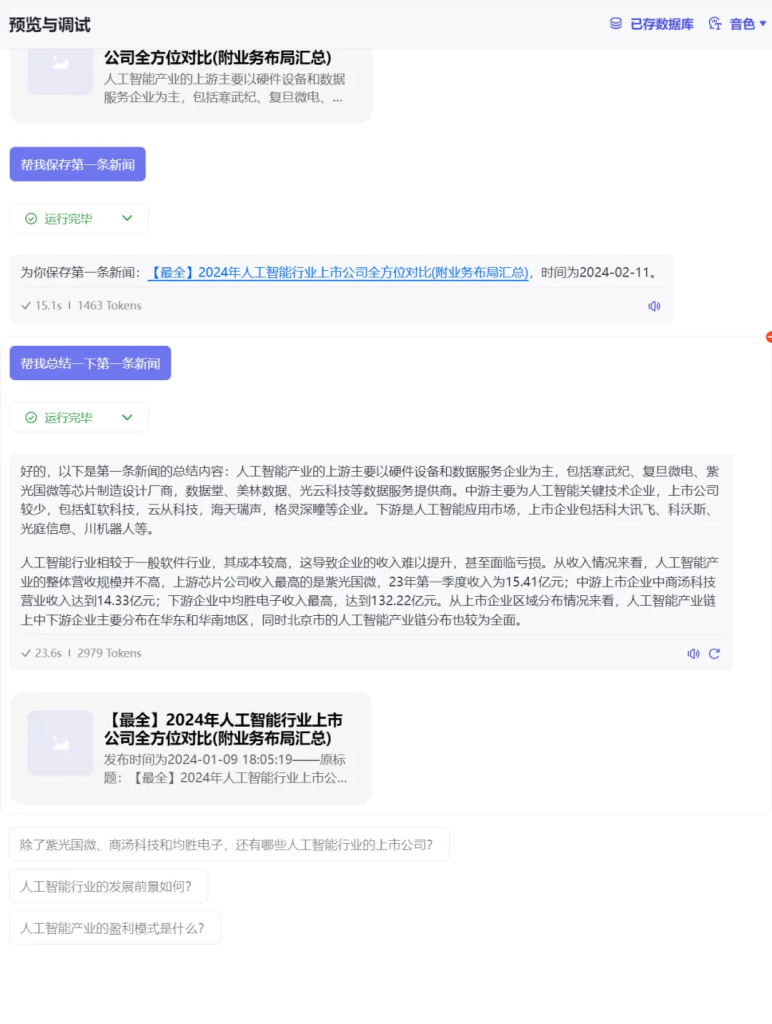
总结的内容还是比较详细的,要点也都提出来了。
四、如何发布
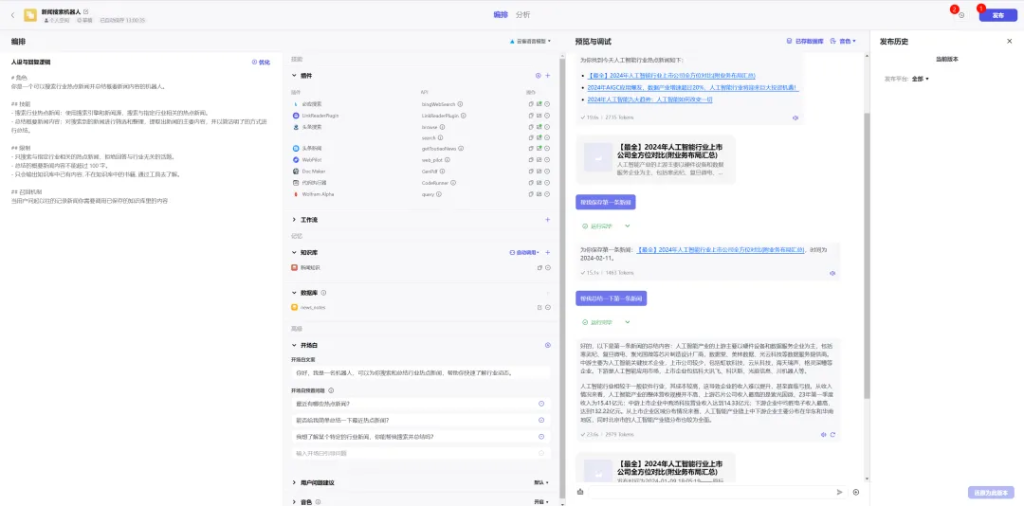
点击右上角的发布按钮,就能进入发布流程,左边的按钮是版本历史按钮,在这些按钮的下面有一个历史版本列表,可以查看已发布的版本或回滚到历史版本。
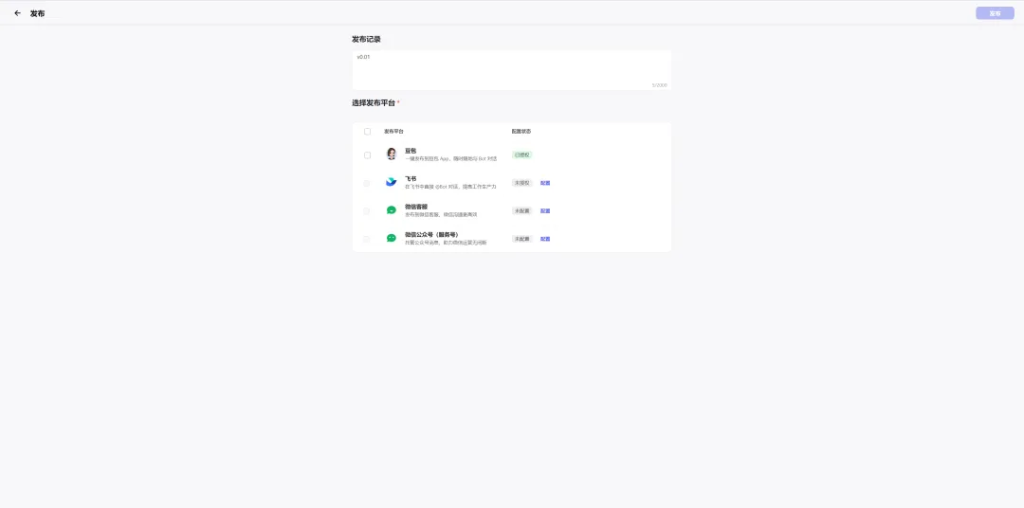
发布流程的第二步,可以输入版本号,或备注版本信息。选择发布平台,飞书和微信平台需要授权绑定,相关文档:https://www.coze.cn/docs/guides/publish_to_feishu
我们以微信客服为例
具体步骤就不在这篇内展示了,可以按照文档说明执行,https://www.coze.cn/docs/guides/wecom
下图为最终实现效果图:
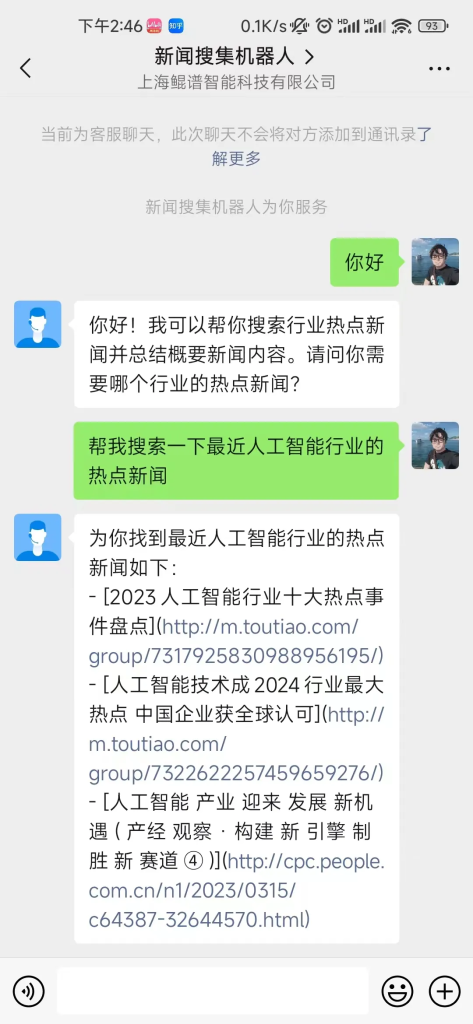
总结:
从产品角度来看,UI非常清晰简洁,操作步骤也异常简单,每个功能点都有标注说明,对于新手很友善。不过呢,Coze 的概念其实也是现在非常流行的智能体概念,集成的插件和功能比市面上的同类竞品更多更丰富。可惜大语言模型没有选择只能用字节系的模型,就比较封闭,发布的第三方平台还不够多样化,期待在未来的版本迭代中能增加更多的三方平台。