

LLama 3.1系列模型重大升级简介
Hi,大家好。扎克伯格诚不欺我,当时在4月份发布Llama3的时候就预告今年夏天会开源405B版本,这不,果然就发布了。这次Meta的LLama系列开源模型迎来了从LLama 3到LLama 3.1的飞跃式升级。本次升级的亮点包括:
- 提供3种不同规模的预训练及指令微调模型,包括LLama 3.1 8B、70B和405B;
- 在英语的基础上,新增7种语言的高质量训练数据;
- 在多个评测基准上取得领先表现;
- 显著提升代码和数学能力;
- 源生模型工具调用能力;
- 支持更长的上下文长度,最高可达128K tokens。
LLama 3.1系列模型已在Hugging Face和Meta的官方GitHub仓库开源。
模型基础信息
Llama 3.1系列模型采用了优化的自回归语言模型架构,并通过监督微调(SFT)和强化学习与人类反馈(RLHF)进行调优,以符合人类的偏好和安全性。以下是各模型的基本信息:
| 模型 | 参数量 (B) | 输入模态 | 输出模态 | 上下文长度 | GQA | 知识截止日期 |
|---|---|---|---|---|---|---|
| Llama 3.1 (8B) | 8 | 多语言文本 | 多语言文本和代码 | 128k | 是 | 2023年12月 |
| Llama 3.1 (70B) | 70 | 多语言文本 | 多语言文本和代码 | 128k | 是 | 2023年12月 |
| Llama 3.1 (405B) | 405 | 多语言文本 | 多语言文本和代码 | 128k | 是 | 2023年12月 |
训练数据与方法
Llama 3.1系列模型使用了新的混合公开在线数据进行训练。所有模型均支持多语言文本输入和输出,并在训练过程中考虑了知识截止日期,以确保模型的知识是最新的。
硬件与软件
Meta利用其自定义训练库、定制的GPU集群和生产基础设施进行了模型的预训练。微调、注释和评估也在生产基础设施上进行。训练过程中使用了总计39.3M GPU小时的计算资源,并在训练过程中实现了净零温室气体排放。
多语言能力提升
Meta团队投入了大量精力扩展和提升多语言预训练及指令微调数据的规模和质量,以增强模型的多语言能力。除了英语,LLama 3.1还针对性地增强了以下7种语言:
- 德语
- 法语
- 西班牙语
- 葡萄牙语
- 意大利语
- 印地语
- 泰语
此外,还特别优化了多语言场景中常见的语言转换问题,显著降低了模型发生意外语言切换的概率。
LLama 3.1模型评测报告
在LLama 3.1系列模型的全新升级中,Meta对LLama 3.1 405B进行了全面的评测。以下是评测结果的详细概述:
大规模模型效果显著提升
与前代Llama 3相比,Llama 3.1在大规模模型上实现了显著的效果提升。在自然语言理解、知识掌握、代码编写、数学推理及多语言处理等多项能力上,Llama 3.1 405B均超越了当前领先的开源模型。
精细微调提升智能水平
在大规模预训练的基础上,Meta进一步对模型进行了精细的微调,以提升其智能水平,使其表现更接近人类。微调过程中,主要专注于以下几个方面:
- 代码、数学、推理、指令遵循、多语言理解等能力的进一步提升。
- 人类价值观对齐,使模型更加有帮助、诚实和安全。
- 微调遵循的原则是在规模化训练的同时减少人工标注,通过多种自动化方法获取高质量、可靠的指令和偏好数据。
微调方法的创新
在微调方法上,Meta采用了以下创新手段:
采用在线模型合并技术减少对齐税,有效提升了模型的基础能力和智能水平。
有监督微调、反馈模型训练以及在线DPO等方法的结合。
LLama 3.1 405B Instruct的全面评估
Meta最新发布的LLama 3.1 405B模型在多个基准测试中展现出了卓越的性能,与其他顶级大语言模型如GPT-4和Claude 3.5 Sonnet不相上下,甚至在某些领域还略胜一筹。让我们详细分析一下各个方面的表现:
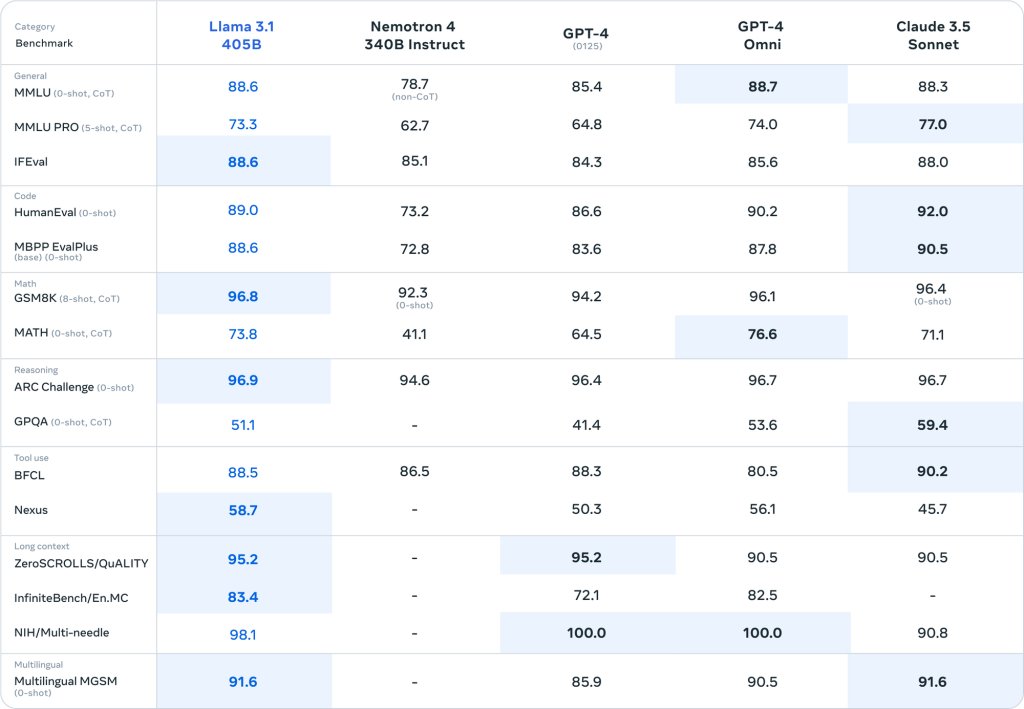
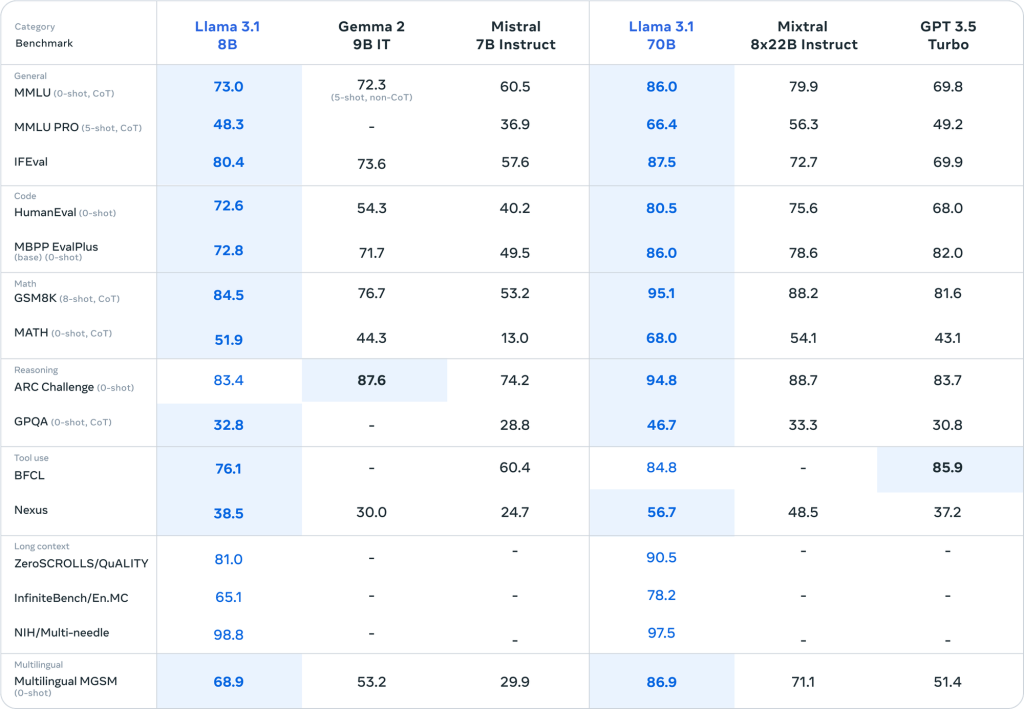
Meta Llama 3.1系列模型在全面评估中的表现证明了其在多语言对话、代码编写、数学推理、逻辑推理、工具使用和长文本处理等方面的卓越能力。
LLama 3.1系列模型亮点介绍
在LLama 3.1系列模型的升级中,Meta专注于多个关键领域的改进,以下是一些显著的亮点:
代码与数学能力提升
Meta致力于提升LLama在代码和数学领域的能力。在代码方面,LLama 3.1在多种编程语言上实现了显著的效果提升。而在数学领域,通过大规模且高质量的数据训练,LLama 3.1 405B Instruct在数学解题能力上取得了飞跃性的进步。
长文本处理能力
LLama 3.1系列中的所有Instruct模型均在32K的上下文长度上进行训练,并利用先进技术扩展至更长的上下文处理能力。
- LLama 3.1 405B Instruct:能够完美处理高达128K上下文长度的信息抽取任务,成为处理长文本任务的理想选择。
- LLama 3.1 70B Instruct:同样支持128K的上下文长度。
- LLama 3.1 8B Instruct:支持128K上下文长度,这对于小型模型来说是非常impressive的。
工具调用能力
这次的Llama3.1引入了直接调用工具的能力,与之前的版本不同,Llama3.1内置了三种调用工具。Meta建议,如果要充分利用这一功能,最好使用Llama3 70b或405b版本。8b版本虽然在前4-5轮对话中表现尚可,但在更长的对话中可能就显得力不从心了。
Llama3内置的三种工具:
- Brave Search: 用于网络搜索
- Wolfram Alpha: 用于复杂数学计算
- Code Interpreter: 允许模型输出Python代码
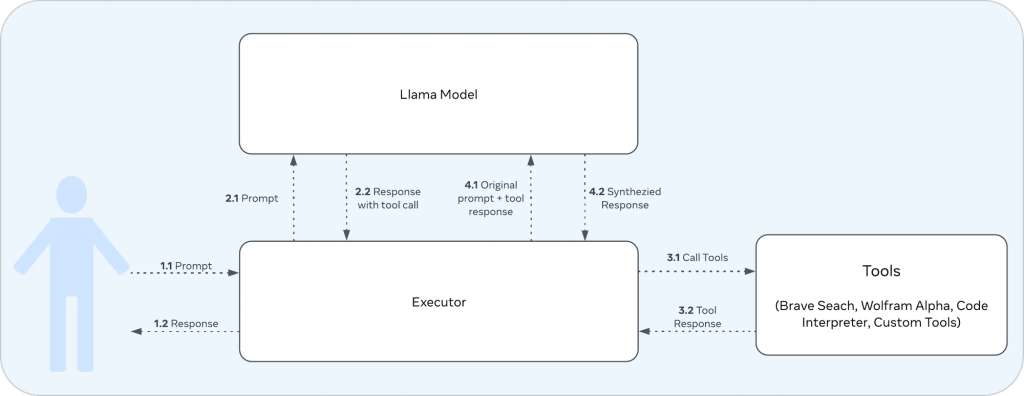
以上这张图是工具调用流程的信息流图
Llama3.1提示词格式支持4种不同的角色:
- system:设置与AI模型交互的上下文
- user:代表与模型交互的人类
- ipython:新引入的角色,语义上表示”工具”,用于标记工具调用的输出
- assistant:代表AI模型生成的响应
基本的提示词格式结构如下:
<|begin_of_text|><|start_header_id|>system<|end_header_id|>
[系统指令]<|eot_id|><|start_header_id|>user<|end_header_id|>
[用户输入]<|eot_id|><|start_header_id|>assistant<|end_header_id|>
[助手回复]安全性表现
在安全性方面,LLama 3.1 405B Instruct在多语言不安全查询类别中展现出了卓越的性能。Meta通过Jailbreak测试数据,并将其翻译成多种语言进行评估,结果显示LLama 3.1 405B Instruct在安全性方面表现出色。
如何使用LLama 3.1
LLama 3.1系列模型已经在Hugging Face和Meta的官方GitHub仓库开源。开发者可以通过以下方式使用LLama 3.1:
- 直接从Hugging Face下载预训练模型权重。
- 使用Hugging Face Transformers库加载模型。
- 通过Meta提供的API进行在线体验和测试。
- 通过Ollama获取权重模型。
Meta还提供了详细的文档和示例代码,帮助开发者快速上手并将LLama 3.1应用到各种场景中。
结语
这次Llama3.1 405b的发布可以算是开源大语言模型的里程碑,这一步不仅标志着开源大型语言模型(LLM)正式迈入了千亿参数的新时代,更预示着技术的深远影响。扎克伯格对这款模型的期望远不止于其在应用开发中的潜力,他更希望Llama系列能够扮演起推动整个生态系统循环发展的关键角色。最后的最后,不得不说扎卡伯格的愿景——Llama系统,其实Llama系列的模型一开始就被设计为一个更庞大系统的一部分(类似于我们现在用的操作系统,windows、OS、Linux等),这些系统可以协调多个组件,包括调用外部工具,类似于现在的智能体。小扎不仅仅只是开源了大语言模型,甚至于支持其模型的组件,比如:Llama Guard 3(多语言安全模型)和Prompt Guard(提示注入过滤器)也相继开源了,从单一的语言模型转变为一个完整的AI系统和生态系统。此时,真想问一下某度的某总,您对此怎么看,哈哈!
项目地址:
GitHub:https://github.com/meta-llama/llama-models/tree/main/models/llama3_1
HuggingFace:https://huggingface.co/meta-llama

