知识表示与专家系统
概述
在人工智能的早期,自上而下创建智能系统的方法(在上一课中讨论过)非常流行。这个想法是从人们那里提取知识,转换成机器可读的形式,然后利用它来自动解决问题。这种方法基于两个重要概念:
- 知识表示(Knowledge Representation)
- 推理(Reasoning)
知识表示
在符号人工智能(Symbolic AI)中,知识是一个重要概念。重要的是要区分知识与信息或数据。例如,我们可以说书籍包含知识,因为人们可以通过学习书籍成为专家。然而,书籍实际包含的被称为数据,我们通过阅读书籍并将这些数据整合到我们对世界的模型中,将这些数据转化为知识。
符号人工智能(Symbolic AI)它指的是以符号和规则为基础,通过符号的操作来表示和处理知识的一种人工智能方法。这种方法强调了知识的形式化和逻辑推理,使得人工智能系统能够模拟人类的思考过程。
💡 ✅ 知识是我们头脑中的东西,代表了我们对世界的理解。它是通过一个积极的学习过程获得的,这个过程将我们接收到的信息片段整合到我们对世界的活跃模型(应该是理解为世界观)中。
我们通常不会严格定义知识,而是通过DIKW金字塔将其与其他相关概念对齐。金字塔包含以下概念:
- 数据(Data)是存在于物理媒介中的东西,如书面文字或口头话语。数据独立于人类存在,并且可以在人们之间传递。
- 信息(Information)是我们在头脑中对数据的解释。例如,当我们听到“计算机”这个词时,我们对它有一定的理解。
- 知识(knowledge)是信息被整合到我们的世界观模型中。例如,一旦我们了解了计算机是什么,我们就开始有了一些关于它是如何工作的、它的成本是多少以及它可以用于什么的一些想法。这些相互关联的概念网络形成了我们的知识。
- 智慧(Wisdom)是我们对世界理解的更深层次,它代表了元知识,例如,关于何时以及如何使用知识的一些概念。
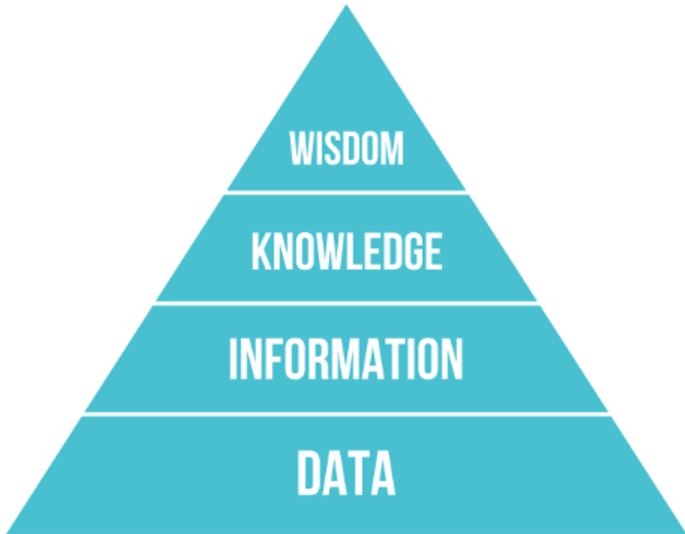
DIKW金字塔模型,来自维基百科
因此,知识表示的问题是要找到一种有效的方法,将知识以数据的形式在计算机内部表示出来,使其能够自动使用。这可以被视为一个连续的谱系:
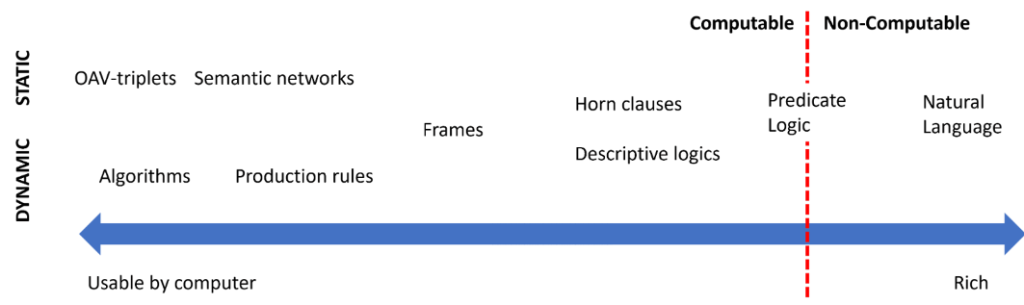
- 如图,以红线为中间线谓词逻辑(Predicate Logic)的左边区域存在一些非常简单的知识表示类型,这些类型可以被计算机有效使用。当知识通过计算机程序来表示时,其最简单的一种方法是算法式( Algorithmic)。然而,这不是表示知识的最好方式,因为它不够灵活。我们头脑中的知识往往是非算法式的。
- 如图,以红线为中间线谓词逻辑(Predicate Logic)的右边区域有如自然语言(Natural Language)这样的表示形式。它是最强大的,但不能用于自动推理。
“Predicate logic”(谓词逻辑)是一种形式逻辑系统,它扩展了命题逻辑,允许我们表达更为复杂的关系和属性。在谓词逻辑中,我们不仅可以讨论命题的真假,还可以讨论对象之间的关系,以及对象所具有的属性。
谓词逻辑是数学、哲学、计算机科学和人工智能等领域中非常重要的工具,因为它提供了一种精确和系统化的方式来表达和推理关于世界的知识。在人工智能中,谓词逻辑常用于构建知识库和进行自动推理。
✅ 思考一分钟,你是如何在你的头脑中表示知识的,并且将其转化为笔记的。是否有某种特定的格式对你来说在帮助记忆方面特别有效?
计算机知识表示的分类
我们可以将不同的计算机知识表示方法分为以下几个类别:
- 网络表示(Network representations):基于我们头脑中相互关联的概念网络。我们可以尝试在计算机中复现相同的网络,以图的形式——即所谓的语义网络。
1.对象-属性-值三元组(Object-Attribute-Value triplets)或属性-值对(Attribute-value pairs):由于图可以在计算机中表示为节点和边的列表,我们可以通过对象、属性和值的三元组列表来表示语义网络。例如,我们可以构建关于编程语言的以下三元组:
| Object | Attribute | Value |
|---|---|---|
| Python | is | Untyped-Language |
| Python | invented-by | Guido van Rossum |
| Python | block-syntax | indentation |
| Untyped-Language | doesn’t have | type definitions |
2. 层次表示(Hierarchical representations):强调我们经常在头脑中为对象创建层次结构的事实。例如,我们知道金丝雀是一种鸟,所有的鸟都有翅膀。我们对金丝雀通常的颜色以及它们的飞行速度也有一定的概念。
- 框架表示(Frame representation):基于将每个对象或对象类别表示为包含槽的框架。槽可能有默认值、值限制,或者存储的可以调用的过程,以获得槽的值。所有的框架形成一个层次结构,类似于面向对象编程语言中的对象层次结构。
- 情景表示(Scenarios):是一种特殊的框架,代表可以随时间展开的复杂情境。
| Slot | Value | Default value | Interval |
|---|---|---|---|
| Name | Python | ||
| Is-A | Untyped-Language | ||
| Variable Case | CamelCase | ||
| Program Length | 5-5000 lines | ||
| Block Syntax | Indent |
3. 程序化表示(Procedural representations)是基于通过在特定条件发生时可以执行的一系列动作来表示知识。
- 产生式规则(Production rules)是允许我们得出结论的“如果-那么”语句。例如,医生可以有一条规则说,如果病人有高烧或者血液中C反应蛋白水平高,那么他有炎症。一旦我们遇到其中一个条件,我们就可以对炎症做出结论,然后将其用于进一步的推理。
- 算法(Algorithms)可以被视为程序化表示的另一种形式,尽管它们几乎从未直接在基于知识的系统中使用。
4. 逻辑(Logic)最初是由亚里士多德提出,作为表示普遍人类知识的一种方式。
- 谓词逻辑(Predicate Logic)作为数学理论太丰富,以至于无法计算,因此通常使用它的一个子集,例如在Prolog中使用的Horn子句。
- 描述逻辑(Descriptive Logic)是一组逻辑系统,用于表示和推理关于对象层次结构的分布式知识表示,如语义网。
专家系统(Expert Systems)
符号人工智能领域早期的一项重要成就是专家系统——这些计算机系统设计用于在特定领域内扮演专家角色。它们利用从一位或多位人类专家那里收集的知识库,并配备了一个推理引擎,用于在这些知识基础上进行逻辑推理。
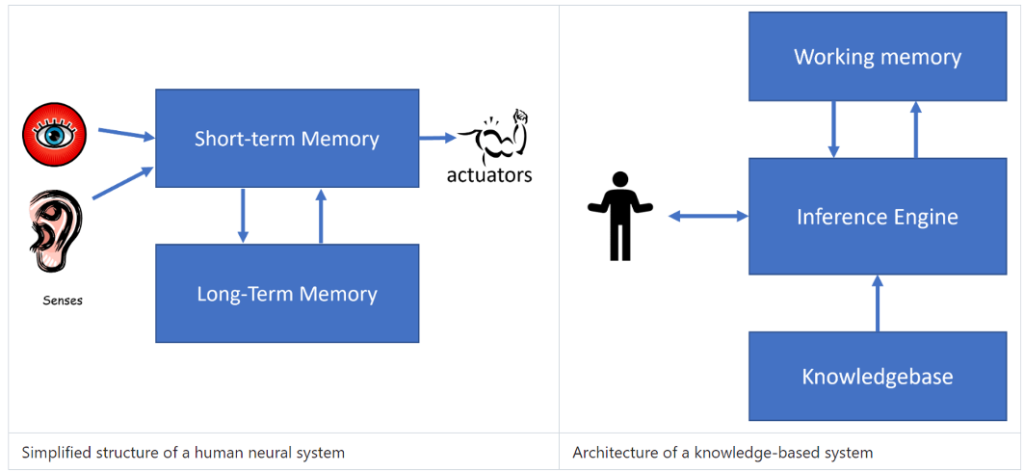
专家系统构建得类似于人类的推理系统,其中包含短期记忆和长期记忆。类似地,在基于知识的系统中,我们区分以下组件:
- 问题记忆(Problem memory):包含了当前正在解决的问题的相关知识,比如病人的体温或血压,是否患有炎症等。这类知识也被称作静态知识,因为它记录了我们对问题当前状态的快照——即所谓的问题状态。
- 知识库(Knowledge base):存储了关于问题领域的长期知识。这些知识是人工从人类专家那里获取的,并且在不同的咨询过程中保持不变。由于它使我们能够从一个问题状态过渡到另一个问题状态,因此也被称作动态知识。
- 推理引擎(Inference engine):负责整个在问题状态空间中搜索的过程,必要时向用户提出问题。它还负责确定每个状态下应该应用的正确规则。
作为一个例子,让我们考虑以下基于动物的物理特征来确定其种类的专家系统:
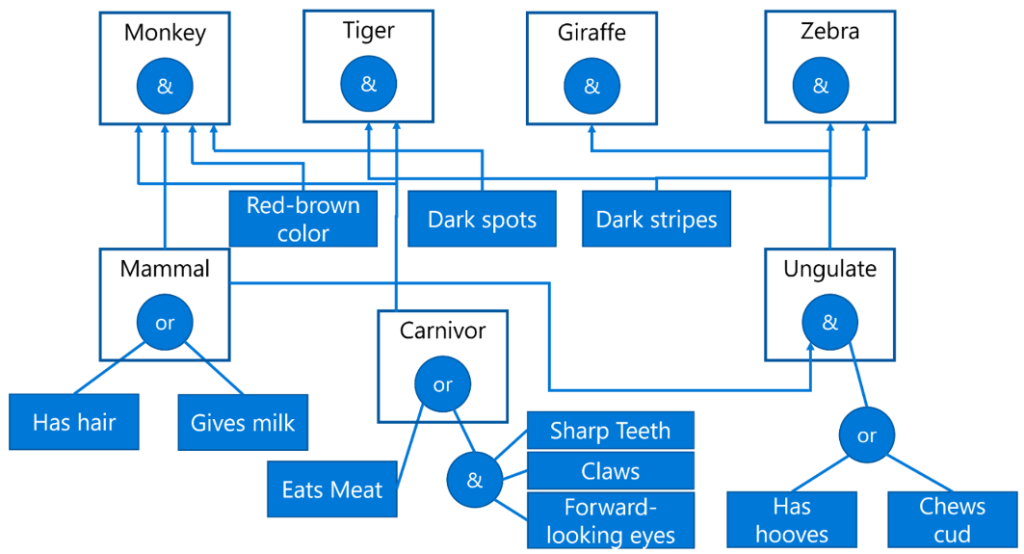
这个图表被称为AND-OR tree,它是一组产生式规则的图形表示。绘制树在从专家那里提取知识之初是有用的。要在计算机内部表示知识,使用规则更为方便:
IF the animal eats meat
OR (animal has sharp teeth
AND animal has claws
AND animal has forward-looking eyes
)
THEN the animal is a carnivore你可以注意到,规则左侧的每个条件和动作实际上是对象(object)-属性(attribute)–值(value)(OAV)三元组。工作记忆包含了与当前正在解决的问题相对应的OAV三元组集合。规则引擎寻找那些其条件得到满足的规则,并对这些规则进行应用,向工作记忆中添加另一个三元组。
✅ 写一个属于你自己的AND-OR树! 例子:
愉快的周末 / \\\\ / \\\\ / \\\\ 运动 休息 / \\\\ / \\\\ / \\\\ / \\\\ 跑步 游泳 睡觉 看电影 | | | |跑步: 穿上跑鞋, 去公园跑步, 感受阳光和微风 游泳: 带上泳衣, 去游泳池或海边游泳, 享受水的清凉 睡觉: 放松身心, 睡个好觉, 为新的一周充电 看电影: 选择一部喜欢的电影, 享受观影的乐趣
前向推理(Forward Inference)VS后向推理(Backward Inference)
上述过程称为前向推理。它始于工作记忆中关于问题的初始数据,随后进入推理循环的执行:
- 检查工作记忆中是否已有目标属性 – 如果有,结束并提供结果。
- 寻找所有当前条件已满足的规则 – 以确定规则的冲突集合。
- 执行冲突解决 – 挑选一个在当前步骤要执行的规则,这可能涉及不同的策略:
- 选择知识库中首个符合条件的规则。
- 随机选择一个规则。
- 选择一个更具体的规则,即在“左侧”(LHS)满足条件最多的规则。
- 应用所选定的规则,并将新知识片段加入到问题状态中。
- 从第一步重新开始循环。
✅ 前向推理通常从已知数据出发,寻找可能的结论;而后向推理则是从目标结论出发,反向寻找支持这一结论的证据或数据。
实施专家系统
实现专家系统可以借助多种工具:
- 采用高级编程语言直接编程。这种方法并不理想,因为基于知识库的系统的核心优势在于知识与推理逻辑是独立分开的。如果可能,领域专家应该无需理解推理过程的细节,就能编写规则。
- 利用专家系统外壳(expert systems shell),这是一个专为使用某种知识表示语言填充知识而设计好的系统。
✍️ 练习:动物推理
Animals.ipynb这是一个有关实现前向和后向推理专家系统的示例
请注意:此例较为简化,仅旨在展示专家系统的基本形态。当您着手构建此类系统时,只有在累积了一定数量的规则,大约200条以上,您才能观察到它的智能行为。在某个阶段,规则复杂到难以全部记忆,这时您可能会开始思考系统为何会做出特定的决策。然而,基于知识系统的一个关键特性在于,您始终能够精确阐释任何决策的形成过程。
本体论(Ontologies )和语义网(Semantic Web)
在20世纪末,人们提出了一个利用知识表示技术对互联网资源进行标注的计划,目的是为了能够检索到与特定查询条件相匹配的资源。这场运动被命名为语义网,它基于以下几个核心概念:
- 一种基于描述逻辑( Description Logics=DL)的特殊知识表示方法。它与框架式知识表示相似,因为它通过属性构建了对象的层级结构,但它具有严格的逻辑语义和推理功能。存在多种DL,它们在表达能力和推理过程的算法复杂性之间寻求平衡。
- 一种分布式的知识表示方式,其中每个概念都通过一个全局统一资源标识符(URI)来表示,使得创建跨越整个互联网的知识层级结构成为可能。
- 一系列基于XML的语言用于描述知识:RDF(资源描述框架)、RDFS(RDF模式)、OWL(本体网语言)。
语义网中的一个核心概念是“本体”。它指的是使用某种形式化的知识表示方法,明确地定义一个问题领域。最简单的本体可能仅仅是问题领域内对象的层级结构,但更复杂的本体将包含可用于推理的规则。
在语义网中,所有的表示都基于三元组。每个对象和每个关系都通过URI进行唯一标识。例如,如果我们想陈述这个人工智能课程是由Dmitry Soshnikov在2022年1月1日开发的——我们可以使用以下三元组:
- <人工智能课程, 开发者, Dmitry Soshnikov>
- 此三元组表明”人工智能课程”的”开发者”是”Dmitry Soshnikov”。
- <人工智能课程, 开发日期, ‘2022-01-01’>
- 此三元组表明”人工智能课程”的”开发日期”是”2022年1月1日”。
在此处,”人工智能课程”、”开发者”、”开发日期”以及”Dmitry Soshnikov”和日期都通过URI来唯一标识,确保它们在语义网上是全球可识别的。
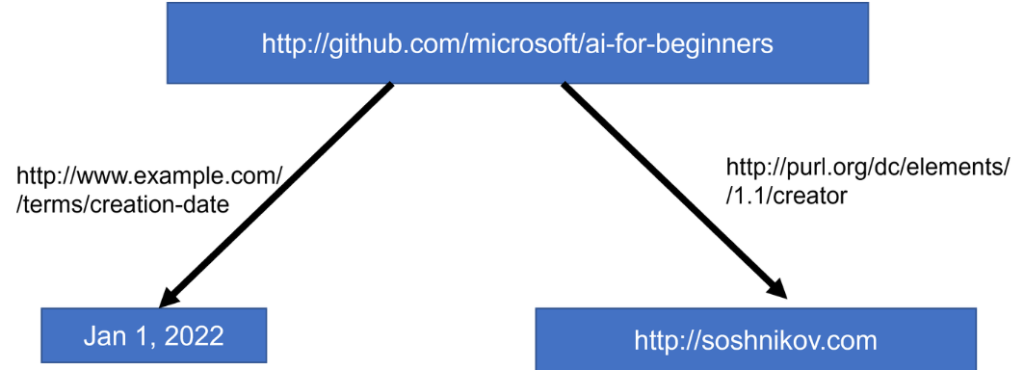
http://github.com/microsoft/ai-for-beginners http://www.example.com/terms/creation-date “Jan 13, 2007”
http://github.com/microsoft/ai-for-beginners http://purl.org/dc/elements/1.1/creator http://soshnikov.com在更复杂的情况下,如果我们想要定义一个创作者列表,我们可以使用RDF(Resource Description Framework,资源描述框架)中定义的一些数据结构。
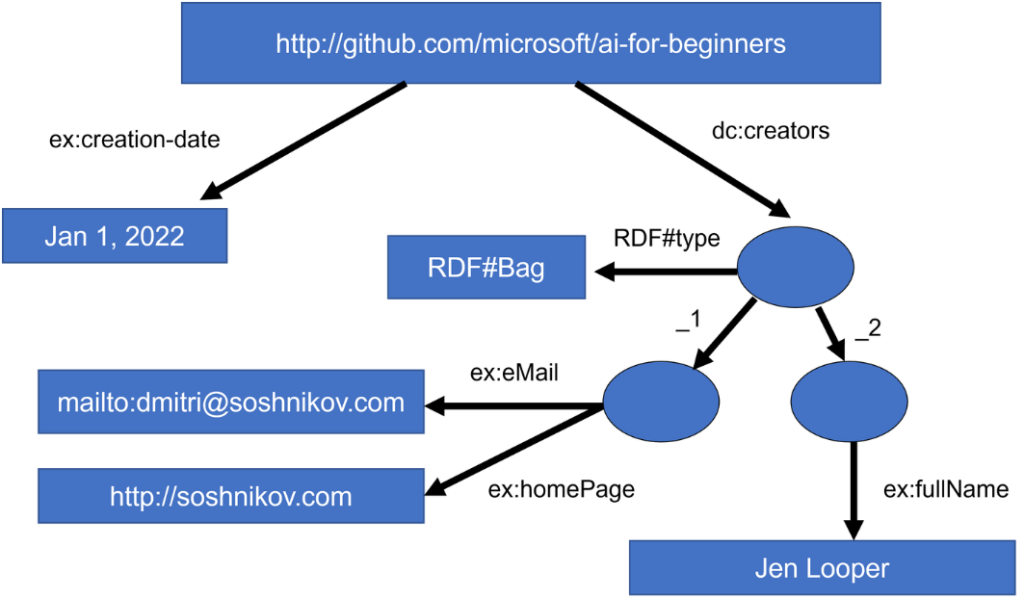
构建语义网的进程在某种程度上因搜索引擎和自然语言处理技术的成功而放缓,这些技术能够从文本中提取出结构化数据。然而,在某些领域,人们仍在积极努力维护本体和知识库。一些值得关注的项目包括:
- WikiData 是与维基百科相关联的一系列机器可读的知识库。大多数数据挖掘自维基百科中的信息框(InfoBoxes),这些是维基百科页面内的结构化内容。你可以使用SPARQL——一种专门为语义网设计的特殊查询语言——来查询WikiData。这里有一个示例查询,展示了人类中最常见的眼睛颜色:
#defaultView:BubbleChart
SELECT ?eyeColorLabel (COUNT(?human) AS ?count)
WHERE
{
?human wdt:P31 wd:Q5. # human instance-of homo sapiens
?human wdt:P1340 ?eyeColor. # human eye-color ?eyeColor
SERVICE wikibase:label { bd:serviceParam wikibase:language "en". }
}
GROUP BY ?eyeColorLabel✅ 如果你想要尝试构建自己的本体论,或者打开现有的本体论,有一个出色的可视化本体编辑器名为”Protégé”。
✍️ 练习:家族本体论
参阅FamilyOntology.ipynb,了解如何利用语义网技术来推理家族关系。我们将采用以常见的GEDCOM格式呈现的家族树和家族关系本体,并构建一个特定个体集合的家族关系图。
示例:微软概念图谱
- 大多数本体论是手工精心构建的。不过,也可以从非结构化数据中挖掘本体论,例如自然语言文本。
- 微软研究院进行了这样的尝试,并开发出了微软概念图谱。
- 这是一个通过“is-a”继承关系组织的大型实体集合。它能够回答问题,例如“微软是什么?”——答案可能是“一个公司,置信度0.87,一个品牌,置信度0.75”。
- 该图谱可以通过REST API访问,或者作为一个列出所有实体对的大型可下载文本文件。
🚀 一个挑战
在与本课程相关的家庭本体论(A Family Ontology)中,你有机会试验其他家族关系。尝试在家族树中探索人们之间的新联系。
🤓复习与自学
在互联网上做一些研究,探索人类尝试量化和系统化知识的领域。研究布鲁姆(Bloom)的分类学,追溯历史,了解人类如何努力理解他们的世界。探究林奈(Linnaeus)是如何创建生物分类法的,以及门捷列夫(Dmitri Mendeleev)是如何为化学元素的描述和分类制定方法的。你还能发现哪些其他有趣的例子?
-以上文章翻译自微软的AI-For-Beginners